
Das Thema Docker beschäftigt mich nach wie vor. Nach den ersten praktischen Anwendungen, die vor allem die Nutzung aus Anwender-Sicht zum Thema hatten, wollte ich nun anhand eines einfachen Beispiels aus der Praxis selbst Docker-Images anlegen und Container zum Laufen bringen. Eine gewisse Inspiration ergab sich aus dem Docker-Meetup Cologne, bei dem das Thema „Patterns in a Containerized World“ behandelt wurde. Insbesondere die dort angesprochenen Best Practices und Beobachtungen der Struktur von Anwendungen, die innerhalb von Containern in Betrieb sind, fanden meine Aufmerksamkeit. Als weiteren Einstieg kann ich einen Vortrag von der Froscon 2015 empfehlen, der anhand eines Beispiels auf die Aufteilung von Diensten in Container und somit Strukturierung einer Anwendung eingeht. Das Beispiel ist insofern sehr gut, als dass es über die Hinweise in zahlreichen Tutorials hinaus geht, bei denen die Einführung eher einfach gehalten ist.
Als Einstieg und tatsächliches Beispiel diente mir eine Rails-Anwendung. Diese besteht aus der Web-Applikation selbst, als Datenbank wird MongoDB eingesetzt. Darüber hinaus sind ebenfalls in Ruby bzw. Rails erstellte Worker vorhanden, die asynchron Aufgaben durchführen, z.B. Caching und Generierung von Dateien. Das Deployment wird in der aktuellen Fassung mittels Capistrano ausgeführt. Das funktioniert auch sehr gut, insofern stellt sich die Frage, ob es überhaupt sinnvoll ist, hier möglicherweise Docker einzusetzen.
Die Antwort lautet wie so oft – it depends… Einerseits funktionieren die Deploy-Skripte, also warum etwas daran ändern. Andererseits sind in einer nächsten Version der Anwendung nicht nur neue Versionen von Rails-, Ruby- etc. notwendig, sondern auch eine weitere Datenbank. Insofern müssten die Deploy-Skripte bereits deshalb angepasst werden. Ruby bzw. Rails sind bzgl. Versionen von Modulen und deren Abhängigkeiten mitunter sehr sensibel. So empfiehlt es sich zum Beispiel, die jeweils benötigte Ruby-Version lokal für den entsprechenden User einzurichten und nicht global pro Server wie bei anderen Programmiersprachen gewohnt. Daher ist es auch nicht sinnvoll, die Version einzusetzen, die mit der jeweiligen Linux-Distribution enthalten ist, sondern auf den Ruby Version Manager (rvm) zurück zu greifen. Insgesamt lässt sich damit eine für den jeweiligen User spezielle und lokale Ruby-Umgebung erstellen. Allein aus diesem Grund sind die Deploy-Skripte recht speziell angelegt. Des Weiteren läuft die aktuelle Umgebung bei einem der beliebten „Cloud“-Anbieter. Dieser bietet nicht nur virtuelle Maschinen, sondern darüber hinaus etliche Tools und HIlfsmittel zum Deployment. Was aber, wenn der Anbieter evtl. gewechselt werden soll? Oder wenn weitere Provider hinzu gefügt werden sollen? Die speziell angepassten Tools bzw. die Provider-eigenen Hilfsmittel können damit nicht eingesetzt werden. Wenn nun Docker-Images eingesetzt würden, könnten diese sehr einfach auf beliebigen Hosts laufen, denn die gesamte Anwendung inkl. aller Abhängigkeiten verbirgt sich darin. Das Deployment beschränkt sich damit mehr oder minder auf den Start des Containers, evtl. ergänzt durch die Übernahme einiger Daten der Datenbank. Auch daher könnte Docker tatsächlich praktisch sein, um provider-unabhängig agieren zu können. Und nicht zuletzt wollte ich das Erstellen von Docker-Images auch einfach an einem realen Beispiel testen, was ein wenig mehr bietet als eine statische Seite mit Nginx auszuliefern.
Aufgrund der eingangs erwähnten Komponenten ergibt sich die Strukturierung bzw. Aufteilung der Container. Den Anfang macht die MongoDB-Datenbank. Des Weiteren existieren Container für die Worker sowie für die Rails-Web-Anwendung. Insgesamt somit in der aktuellen Fassung minimal drei Container. Da ich die Layer von Docker ausnutzen wollte und sowohl Worker als auch Web-Anwendung auf derselben Codebasis laufen, habe ich folgende Strukturierung festgelegt:
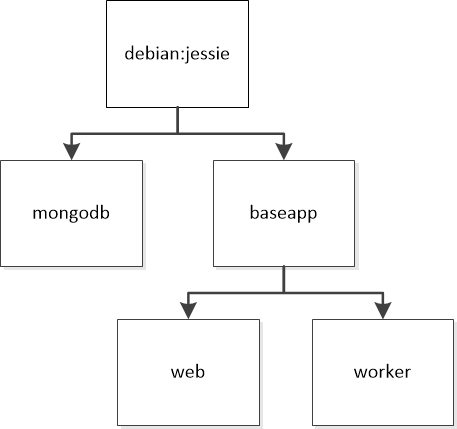
Um mir das Leben ein wenig einfacher zu machen, nutze ich das offizielle Debian-„jessie“-Image als Basis. Das MongoDB-Image wird direkt daraus erstellt. Die Images für Worker und Web-Anwendung wiederum legen dasselbe Basis-Image zugrunde. Dieses beinhaltet einerseits Debian, andererseits die komplette Rails-Umgebung inkl. der Anwendung für Worker und Web. Da diese aus demselben Quellcode bestehen, hielt ich es für sinnvoll, ein gemeinsames Basis-Image einzurichten. Die Unterschiede der Images bestehen letztlich nur darin, dass beim Worker-Image eben die Worker gestartet werden und beim Web-App-Image die Rails-Anwendung für die Web-Anwendung. Insgesamt ist die Struktur somit noch sehr einfach gehalten.
Das erste Dockerfile ist für MongoDB zuständig. Zugegebenermaßen habe ich es weitestgehend kopiert – und zwar vom Autor einiger hervorragender Images, die ich bereits im ersten Artikel über Docker zitiert habe.
FROM debian:jessie
MAINTAINER Ralf Geschke <ralfkuerbis.org>
# mostly taken from https://github.com/sameersbn/docker-mongodb
ENV MONGO_USER=mongodb \
MONGO_DATA_DIR=/var/lib/mongodb \
MONGO_LOG_DIR=/var/log/mongodb
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
ca-certificates curl \
numactl \
&& rm -rf /var/lib/apt/lists/*
RUN apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10 \
&& echo 'deb http://downloads-distro.mongodb.org/repo/debian-sysvinit dist 10gen' | tee /etc/apt/sources.list.d/mongodb.list \
&& apt-get update \
&& apt-get install -y mongodb-10gen \
&& echo "smallfiles = true\r\nreplSet = xyz\r\n" >> /etc/mongodb.conf \
&& rm -rf /var/lib/apt/lists/*
COPY entrypoint.sh /sbin/entrypoint.sh
RUN chmod 755 /sbin/entrypoint.sh
EXPOSE 27017/tcp
VOLUME ["${MONGO_DATA_DIR}"]
ENTRYPOINT ["/sbin/entrypoint.sh"]
CMD ["/usr/bin/mongod"]
Unterschiede bestehen in der hier eingesetzten Version von MongoDB, denn die Anwendung setzt genau die Version 2.4 voraus.
Das dazu gehörige Startskript namens entryfile.sh sieht wie folgt aus:
#!/bin/bash
set -e
create_data_dir() {
mkdir -p ${MONGO_DATA_DIR}
chmod -R 0755 ${MONGO_DATA_DIR}
chown -R ${MONGO_USER}:${MONGO_USER} ${MONGO_DATA_DIR}
}
create_log_dir() {
mkdir -p ${MONGO_LOG_DIR}
chmod -R 0755 ${MONGO_LOG_DIR}
chown -R ${MONGO_USER}:${MONGO_USER} ${MONGO_LOG_DIR}
}
create_data_dir
create_log_dir
# allow arguments to be passed to mongod
if [[ ${1:0:1} = '-' ]]; then
EXTRA_ARGS="$@"
set --
elif [[ == mongod || == $(which mongod) ]]; then
EXTRA_ARGS="${@:2}"
set --
fi
# default behaviour is to launch mongod
if [[ -z ]]; then
echo "Starting mongod..."
exec start-stop-daemon --start --chuid ${MONGO_USER}:${MONGO_USER} \
--exec $(which mongod) -- --config /etc/mongodb.conf ${EXTRA_ARGS}
else
exec "$@"
fi
Docker-Images werden grundsätzlich erstellt mit dem Kommando
docker build -t name .
Das setzt voraus, dass die Datei namens Dockerfile im aktuellen Verzeichnis liegt. Der Name des Images wird durch den Parameter -t bestimmt.
Insofern wird das MongoDB-Image erstellt mit:
docker build -t xyz-mongodb .
Danach kann daraus der Container gestartet werden. Dafür habe ich mir die Kommandos in ein Shell-Skript gepackt:
#!/bin/bash mkdir -p /srv/docker/xyz/mongodb/data docker run -d --name mongodb --volume /srv/docker/xyz/mongodb/data:/var/lib/mongodb xyz-mongodb
Anmerkung: xyz ist hier ein beliebiger Prefix oder auch Namensraum, etwa der Name der Anwendung. Um die Beispiele neutral zu halten, habe ich dafür xyz gewählt.
Zunächst wird zur Speicherung der Daten ein Verzeichnis „/srv/docker/xyz/mongodb/data“ angelegt, was als Volume in den Container gemountet wird. Der Name des Containers wird einfach als „mongodb“ festgelegt, und der Container aus dem anfangs erstellten Image „xyz-mongodb“ erzeugt.
Für das „richtige“ Deployment müssten die Images natürlich auf einem Repository liegen, was von den Servern aus erreicht werden kann, analog zu Docker Hub. Für die ersten Tests habe ich darauf verzichtet, so dass die Erstellung der Images und der Start der Container auf einem Host erfolgen. Nur so sind die Images unter den entsprechenden Namen erreichbar.
Als nächstes erfolgt die Erstellung des Basis-Images, genannt xyz-baseapp. Zunächst wieder das Dockerfile:
FROM debian:jessie
MAINTAINER Ralf Geschke <ralf@kuerbis.org>
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential ca-certificates curl patch gawk g++ gcc make libxml2-dev libxslt-dev sudo git \
openssl libreadline6 libreadline6-dev zlib1g zlib1g-dev libssl-dev \
libyaml-dev libsqlite3-dev sqlite3 autoconf libc6-dev ncurses-dev openssh-client zip \
automake autoconf libtool libc6-dev bison pkg-config libffi-dev libgdbm-dev libncurses5-dev \
imagemagick ghostscript supervisor \
&& mkdir -p /var/log/supervisor \
&& rm -rf /var/lib/apt/lists/*
RUN groupadd -r deploy && useradd -ms /bin/bash -g deploy -G sudo deploy
RUN mkdir /home/deploy/.ssh
COPY ssh/* /home/deploy/.ssh/
RUN chown -R deploy:deploy /home/deploy/.ssh && chmod og-rw /home/deploy/.ssh/id*
USER deploy
WORKDIR /home/deploy
RUN gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 && \
\curl -sSL https://get.rvm.io | bash -s stable
RUN /bin/bash -l -c "source /home/deploy/.rvm/scripts/rvm && rvm requirements && rvm install 1.9.3 && gem install bundler"
RUN git clone git@example.com/xyz/application.git
RUN /bin/bash -l -c "source /home/deploy/.rvm/scripts/rvm \
&& if [ -f /home/deploy/xyz/.rvm ]; then rm /home/deploy/xyz/.rvm; fi \
&& cd /home/deploy/xyz \
&& gem install debugger -v '1.6.8' \
&& gem update debugger-ruby_core_source \
&& bundle install "
Die Schritte zur Generierung des Images sind analog zum MongoDB-Beispiel, das Kommando lautet hier:
docker build -t xyz-baseapp .
Dieses Image bedarf einiger Erläuterungen. Zunächst werden einige Abhängigkeiten bzw. Pakete installiert. Darunter alles, was von der Rails-Anwendung vorausgesetzt wird, sowie für den Start der Anwendung bzw. der Worker das Programm Supervisor, was sich selbst A Process Control System“ nennt.
Die danach folgenden Anweisungen dienen zur Einrichtung eines Users namens „deploy„. Unter dieser User-ID soll die Anwendung später laufen. Ebenfalls wird für diesen User die Ruby-Umgebung eingerichtet, und zwar mit Hilfe von rvm. Der Schritt hat insgesamt die meiste Zeit und das meiste Experimentieren gefordert, denn üblicherweise legt man die Umgebungsvariablen fest, indem das Skript /home/deploy/.rvm/scripts/rvm einmalig in die .bashrc eingebunden wird, so dass der User beim Einloggen die Umgebung erhält, d.h. die lokale Ruby-Installation wäre damit verfügbar. Da hier jedoch keine zunächst keine Shell existiert, muss diese zunächst aufgerufen werden. Danach werden die Umgebungsvariablen mittels „source“ bereit gestellt, anschließend erfolgt die Installation von Ruby in genau der benötigten Version.
Danach wird mittels git die Anwendung in das Home-Verzeichnis gebracht. Das nächste Kommando ruft wiederum die Shell auf, in der alle Schritte zur Installation der Abhängigkeiten bzw. Gems enthalten sind.
Ich habe mich hier absichtlich für das Vorgehen entschieden, die kompletten Quelltexte der Anwendung in das Image zu packen. Natürlich wäre es auch möglich gewesen, die Quelltexte außerhalb des Images zu lagern und nur das entsprechende Verzeichnis hinein zu mounten. Dafür spricht, dass die Quelltexte leichter aktualisiert werden könnten. Jedoch wäre dafür ein Ein- bzw. Zugriff auf den Server notwendig, auf dem der Container letztlich läuft. Das widerspricht meines Erachtens der Auffassung, dass der Container die komplette Anwendung beinhalten soll. Sicherlich gibt es Grenzfälle, so beinhaltet die Anwendung aktuell auch statische Dateien, die letztlich nur ausgeliefert werden bzw. bei denen Rails keine Rolle spielt. Diese könnten genauso gut von einem davor geschalteten Webserver ausgeliefert werden (siehe Hinweis weiter unten). Ein Nachteil könnte ebenfalls sein, dass bei einer neuen Version der Anwendung das Docker-Image neu gebaut und installiert werden muss. Ohne durchgängige Automatisierung verzögert dieses Vorgehen somit ein zügiges Deployment. Ebenfalls sollten Sicherheitsaspekte berücksichtigt werden – der ssh-Key zum Zugriff auf den Git-Server bleibt momentan im Image und landet somit später im Container. Falls das nicht erwünscht ist, kann der Key nach dem erfolgreichen „git clone“ Kommando natürlich auch wieder entfernt werden. Die Quelltexte könnten auch lokal vorliegen bzw. in einem vorhergehenden Schritt auf den Build-Rechner kopiert und von dort in das entsprechende Verzeichnis kopiert werden. Wie üblich führen hier mehrere Wege zum Ziel.
Nach der Ausführung des bundle-Kommandos ist das Image vorbereitet und dient als Basis für das Worker- sowie Web-App-Image. Da das Basis-Image nicht direkt verwendet wird, sondern nur zur Vererbung an die produktiven Images dient, muss es nicht als Container gestartet werden.
Das Dockerfile für die Worker kann demzufolge sehr kurz gehalten werden:
FROM xyz-baseapp MAINTAINER Ralf Geschke <ralf@kuerbis.org> USER deploy WORKDIR /home/deploy COPY app/Procfile /home/deploy/xyz/Procfile COPY app/.env /home/deploy/xyz/.env USER root COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf CMD ["/usr/bin/supervisord"]
Zum Start der Worker dient in dieser Anwendung der Process Manager foreman. In der Datei Procfile wird angegeben, welche Prozesse gestartet werden sollen. Des Weiteren sind in der Datei .env einige Umgebungsvariablen zur Konfiguration, etwa die MongoDB-URL, enthalten. Auf eine detaillierte Darstellung verzichte ich hier, da grundsätzlich jedes Programm gestartet werden kann. Entscheidend für die hier angegebene Konfiguration war, dass die Anwendung unter einem speziellen User, hier „deploy“ läuft, und vor dem Start die Ruby-Umgebung initialisiert werden muss, so dass die User-spezifische Ruby-Variante und nicht die System-Installation verwendet wird. Siehe dazu folgendes Config-File von Supervisor:
[supervisord] nodaemon=true [program:foreman] directory = /home/deploy/xyz user = deploy command = /bin/bash -c "cd /home/deploy/xyz && source /home/deploy/.rvm/scripts/rvm && exec foreman start"
Das von Supervisor aufgerufene Programm ist somit zunächst die Bash, in der zunächst in das Home-Verzeichnis von deploy gewechselt wird, anschließend wird die lokale bzw. User-eigene Ruby-Umgebung initialisiert und danach „foreman“ gestartet.
Analog zu diesem Beispiel wird etwa in der Docker-Dokumentation von Supervisord der Apache Webserver gestartet, während sshd keinen derartigen Umweg über die Bash benötigt und direkt aufgerufen werden kann.
Der Container wird gestartet mit:
sudo docker run --name xyzworker --link mongodb:mongodb -t -i xyz-worker
Da dies zunächst alles testweise eingerichtet ist, habe ich hier auf den Start als Daemon (Option -d) verzichtet. D.h. im realen Leben würden die Optionen -d und –restart-always hinzugefügt werden, damit z.B. nach einem Reboot die Anwendung wieder automatisch gestartet wird.
Die Angabe „–link mongodb:mongodb“ stellt einen Link für den MongoDB-Container zur Verfügung. Damit erthält der xyzworker-Container die Möglichkeit, den MongoDB-Container einfach unter dem Hostnamen „mongodb“ zu erreichen. Für weitere Details zum Linken von Containern verweise ich wieder auf die Docker-Dokumentation.
Als letztes folgt das Dockerfile für die Web-Anwendung:
FROM xyz-baseapp MAINTAINER Ralf Geschke <ralf@kuerbis.org> USER deploy WORKDIR /home/deploy COPY app/Procfile /home/deploy/xyz/Procfile COPY app/.env /home/deploy/xyz/.env USER root COPY supervisord.conf /etc/supervisor/conf.d/supervisord.conf EXPOSE 3000/tcp CMD ["/usr/bin/supervisord"]
Die Erstellung des Images erfolgt analog zum Worker-Image.
Das Supervisor-Config-File sieht ebenfalls der Worker-Supervisor-Konfiguration sehr ähnlich:
[supervisord] nodaemon=true [program:xyzapp] directory = /home/deploy/xyz user = deploy command = /bin/bash -c "cd /home/deploy/xyz && source /home/deploy/.rvm/scripts/rvm && rails server -b 0.0.0.0"
Anstatt das Kommando „foreman“ wird hier der Rails-eigene Entwicklungs-Webserver WEbrick gestartet. Auch dieses Kommando zeigt, dass es sich um einen Test-Case handelt, der zunächst für die lokale Entwicklung gedacht war. In einer Produktionsumgebung könnte man z.B. Unicorn oder Thin einsetzen, die sich um die Auslieferung der Rails-Inhalte kümmern. Üblicherweise wird davor ein Webserver, z.B. Nginx geschaltet, der statische Dateien direkt ausliefert, aber auch zur Lastverteilung auf mehrere Rails-Backends dienen kann. Führt man die „Containerisierung“ konsequent weiter, könnte Nginx in einem weiteren Container Platz finden, der sich wiederum des oder der Rails-Backends bedient.
Der Start der Web-Anwendung erfolgt wie gewohnt:
sudo docker run -p 3000:3000 --name xyzweb --link mongodb:mongodb -t -i xyz-web
Damit sind alle Komponenten der Anwendung vorhanden, die nun auf dem jeweiligen Host unter dem Port 3000 erreicht werden kann. Um es noch mal zu verdeutlichen – die genannte Konfiguration diente ausschließlich zu Testzwecken. Die vielen manuellen Schritte zum Starten der Container würde man auf Produktivsystemen sicherlich automatisieren wollen. Dazu kann etwa Docker-Compose eingesetzt werden. Ganz zu schweigen von der Einrichtung kompletter für Docker vorbereitete Maschinen bzw. Cluster. Oder die Verwendung innerhalb Amazon AWS (EC2 Container Service) oder Google Cloud Platform (Container Engine)…
Momentan experimentiere ich erstmal ein wenig mit Docker-Machine und daran anschließend Docker-Swarm für bestehende VMs unter Ubuntu. Doch das ist eher ein Thema für einen weiteren Blog-Eintrag…




Vielen Dank! Wollt ich nur mal sagen.