
Vor knapp einem Monat hat Docker einige neue Features angekündigt, die mit der Docker Engine Version 1.12 erscheinen. Zwar ist diese Version bislang noch im Beta- bzw. Release-Candidate-Status, aber aufgrund der doch recht umfassenden Änderungen lohnt es sich dennoch, sich vor offizieller Freigabe damit zu beschäftigen.
Docker 1.12, aus alt mach neu
Vorweg sei erwähnt, dass die Änderungen doch einschneidender sind, als die minimale Erhöhung der Versionsnummer vermuten lässt. Die neuen Features zur Einrichtung eines Docker Swarms, aber auch zur Erstellung von Services und darauf basierenden Skalierung und Orchestrierung lassen eher den Schluss zu, dass es sich um völlig neue Tools handelt, als um die Erweiterung eines vorhandenen. Glücklicherweise lassen sich die bisherigen Konfigurationen bislang auch weiterhin verwenden, aber vermutlich wird es nur eine Frage der Zeit sein, bis z.B. die Images für den Swarm Agent nicht mehr gewartet werden und der Umstieg auf den neuen Swarm mode unumgänglich erscheint.
Docker Swarm (mode)
Dieser Artikel beschäftigt sich daher auch nur mit einem Teil der neuen Features, und zwar lautete das Ziel, einen bestehenden Docker Swarm, der mittels docker-machine eingerichtet wurde, in einen neuen Docker Swarm umzuwandeln. Dabei handelte es sich jedoch eher um einen Abriss mit anschließendem Neubau, dazu später mehr. Die Voraussetzungen waren wie folgt – ein Docker Swarm auf mehreren VMs in einem privaten Netzwerk, somit waren alle Ports untereinander freigeschaltet, es mussten keine Änderungen an einer Firewall oder ähnliches durchgeführt werden. Wenn der Swarm z.B. bei AWS EC2 betrieben wird, müsste ein weiterer Port zur Kommunikation freigegeben werden (TCP 2377), während die Ports für Consul (8500. 8300-8302) nicht mehr benötigt werden.
Der Docker Swarm wurde ursprünglich mit docker-machine und SSH per generic Treiber eingerichtet. Der User hat dabei alle Rechte, docker auf den jeweiligen Nodes auszuführen, falls noch nicht geschehen, sollte der User der Gruppe „docker“ hinzugefügt werden, z.B.:
sudo usermod -aG docker geschke
Die Liste der beteiligten Docker Hosts liest sich wie folgt:
geschke@connewitz:~$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS connewitz - generic Running tcp://192.168.10.60:2376 v1.11.2 kaditz - generic Running tcp://192.168.10.39:2376 miltitz v1.11.1 lausen - generic Running tcp://192.168.10.64:2376 v1.11.1 lindenau - generic Running tcp://192.168.10.66:2376 miltitz v1.11.1 miltitz - generic Running tcp://192.168.10.65:2376 miltitz (master) v1.11.1 pirita - generic Running tcp://192.168.10.72:2376 miltitz v1.11.2 tolkewitz - generic Running tcp://192.168.10.43:2376 miltitz v1.11.1 tondi - generic Running tcp://192.168.10.73:2376 miltitz v1.11.2
Als Client wird die VM „connewitz“ eingesetzt, d.h. dort ist docker-machine installiert, alle weiteren Aktionen werden von dieser VM ausgeführt. Beim bisherigen Swarm war dieser Docker Host tatsächlich nicht Bestandteil des Swarms, sondern diente nur als Client zu administrativen Zwecken. Auf der VM namens „lausen“ ist hingegen Consul installiert, somit ist diese Maschine zwar Voraussetzung für den Betrieb des Swarms, aber der Host ist nicht im Swarm mit eingebunden.
Weiterhin wurden die noch unterschiedlichen Versionen der Docker-Engine zunächst aktualisiert, so dass nach dem Update einheitlich die Version 1.11.2 eingerichtet war.
Docker Swarm alt
Da die bisherige Swarm-Installation nicht mehr benötigt wurde, sind die Docker-Container für swarm-agent, swarm-agent-master und consul heruntergefahren und gelöscht worden. Somit wurde der vorherige Swarm letztlich gelöscht.
geschke@connewitz:~$ docker $(docker-machine config --swarm miltitz) stop consulnode02 consulnode01 geschke@connewitz:~$ docker $(docker-machine config --swarm miltitz) rm consulnode02 consulnode01
Entfernen der swarm-Container auf dem Master:
geschke@connewitz:~$ docker $(docker-machine config miltitz) stop swarm-agent swarm-agent-master swarm-agent swarm-agent-master geschke@connewitz:~$ docker $(docker-machine config miltitz) rm swarm-agent swarm-agent-master swarm-agent swarm-agent-master
Ebenfalls wurde auf den anderen Docker-Hosts, die nicht Master waren, der jeweilige swarm-agent abgeschaltet und gelöscht, z.B.:
geschke@connewitz:~$ docker $(docker-machine config pirita) stop swarm-agent swarm-agent geschke@connewitz:~$ docker $(docker-machine config pirita) rm swarm-agent swarm-agent
Nachdem somit alle Container entfernt worden waren, die letztlich die Infrastruktur eines Swarm bilden, wurde der Versuch, den Swarm anzusprechen, folglich mit einer Fehlermeldung quittiert:
geschke@connewitz:~$ docker $(docker-machine config --swarm miltitz) ps Error running connection boilerplate: Connection to Swarm cannot be checked but the certs are valid. Maybe swarm is not started CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES geschke@connewitz:~$
Ein paar Restbestände gibt es dennoch – und zwar aufgrund der vorherigen Einrichtung mittels docker-machine. Da bei der Einrichtung durch docker-machine die ursprüngliche Konfiguration in einem config.json-File gespeichert wurde (z.B. .docker/machine/machines/miltitz/config.json), wird auch bei Ausführen von docker-machine ls der bisherige Swarm nach wie vor angezeigt. Das soll hier aber nicht weiter stören.
Anschließend wude das Update auf die für den Swarm mode notwendige Version 1.12 der Docker-Engine durchgeführt. Diese ist noch im Beta-Stadium für Windows und Mac, unter Ubuntu liegt sie aktuell als Release-Candidate vor. Bei der Erstellung dieses Artikels war v1.12.0-rc4 aktuell.
Docker Swarm Mode neu
Bei Ubuntu liegt die Version 1.12.0-rc4 im „experimental“-Repository vor, insofern ist zunächst die Datei mit den Ubuntu-Paketquellen zu ändern. Auf allen Hosts wurde daher in die Datei /etc/apt/sources.list.d/docker.list folgendes eingetragen, d.h. die Angabe von „main“ durch „experimental“ ersetzt:
deb https://apt.dockerproject.org/repo ubuntu-xenial experimental
Anschließend wurde die Docker-Engine mit den üblichen Kommandos auf den neuesten Stand gebracht:
sudo apt-get update sudo apt-get upgrade
Bei einigen der VMs gab es jedoch Konflikte beim Upgrade, da die Konfiguration unter /etc/default/docker überschrieben werden sollte. Das lag zum Teil auch in der Historie begründet, denn einige der VMs sind von einer älteren Ubuntu-Version upgraded worden, andere waren etwas neuer und direkt mit Ubuntu 16.04 und einer neueren Docker-Version eingerichtet. Bei den neueren Maschinen war die Konfiguration in der Datei /etc/systemd/system/docker.service gespeichert, während die älteren die Datei /etc/default/docker benutzen. Da die Optionen relativ schnell wieder hergestellt werden konnten, wurde im Konfliktfall die „Version des Paket-Betreuers“ installiert.
Das darauf folgende Update war erfolgreich, wie der Blick auf docker info verriet:
geschke@connewitz:/home/geschke# docker info Containers: 4 Running: 0 Paused: 0 Stopped: 4 Images: 36 Server Version: 1.12.0-rc4 Storage Driver: btrfs [...]
Die übrigen Maschinen wurden analog updated, bzw. wurde die Möglichkeit genutzt, sich von der Client-Maschine (d.h. diejenige mit docker-machine) auf den anderen VMs einzuloggen, etwa:
docker-machine ssh kaditz
Nach der erfolgreichen Update-Prozedur war jedoch der direkte Zugriff auf die Docker-Engine vom Client aus nicht mehr möglich:
geschke@connewitz:~$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS connewitz - generic Running tcp://192.168.10.60:2376 v1.12.0-rc4 kaditz - generic Running tcp://192.168.10.39:2376 miltitz Unknown Unable to query docker version: Cannot connect to the docker engine endpoint [...]
Eigentlich war dies auch logisch, denn die bisherigen Optionen wurden überschrieben, so dass die Docker-Engine nur noch in der Default-Einstellung auf dem lokalen Socket verfügbar war. Die bisherigen Opeionsn fehlen somit, diese waren::
DOCKER_OPTS='-H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock --tlsverify --tlscacert /etc/docker/ca.pem --tlscert /etc/docker/server.pem --tlskey /etc/docker/server-key.pem --label instance=large --label provider=generic --cluster-store=consul://192.168.10.64:8500 --cluster-advertise=eth0:2376'
Die einzelnen Docker-Hosts sollten jedoch weiterhin per API, insofern auf dem Port 2376 erreichbar sein. Da der neue Swarm jedoch Consul nicht mehr verwendet, wurden die entsprechenden Angaben entfernt, so dass die Optionen nur noch wie folgt lauteten:
DOCKER_OPTS='-H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock --tlsverify --tlscacert /etc/docker/ca.pem --tlscert /etc/docker/server.pem --tlskey /etc/docker/server-key.pem --label instance=large --label provider=generic'
Nachdem die Optionen entsprechend erweitert wurden, war auch die Docker-Engine mit ihrer API wieder verfügbar:
geschke@connewitz:~$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS connewitz - generic Running tcp://192.168.10.60:2376 v1.12.0-rc4 kaditz - generic Running tcp://192.168.10.39:2376 miltitz v1.12.0-rc4 [...]
Auf den neueren VMs wurden erst gar keine Konflikte beim Update-Prozess genannt, dabei bliebt die Frage, wo die Konfiguration der Docker-Engine stattfindet. Eine Antwort lieferte systemctl:
geschke@pirita:/etc/default# sudo systemctl status docker
● docker.service
Loaded: loaded (/etc/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Sa 2016-07-16 22:33:19 CEST; 4min 13s ago
Main PID: 894 (dockerd)
Tasks: 20
Memory: 89.7M
CPU: 1.071s
CGroup: /system.slice/docker.service
├─894 dockerd -H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock --storage-driver btrfs --tlsver
└─972 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --shim dock
Hierbei wurde /etc/systemd/system/docker.service genutzt, auch darin wurden die Consul-spezifischen Optionen entfernt. Auf einer der VMs wurde diese Änderung zunächst nicht durchgeführt, d.h. dort waren die Parameter für Consul (--cluster-store=consul://192.168.10.64:8500 --cluster-advertise=eth0:2376) noch vorhanden. Beim späteren Einrichten der Swarm Nodes wurde daraufhin eine Fehlermeldung ausgegeben:
geschke@connewitz:~$ docker $(docker-machine config miltitz) swarm join --secret 5h4v1j8vvtkubib4rvaxysysf --ca-hash sha256:1be873d3f8248c3da7365597ad1fda0685b0afa4262763f9502f824b273f3f65 --listen-addr $(docker-machine ip miltitz) 192.168.10.60:2377 Error response from daemon: --cluster-store and --cluster-advertise daemon configurations are incompatible with swarm mode
Somit wird auch klar, dass der bisherige Swarm nicht mit dem neuen Swarm mode kompatibel ist, insofern heißt es entweder – oder.
Nachdem alle Vorbereitungen abgeschlossen waren, sieht die Liste der Docker-Maschinen wie folgt aus:
geschke@connewitz:~$ docker-machine ls NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS connewitz - generic Running tcp://192.168.10.60:2376 v1.12.0-rc4 kaditz - generic Running tcp://192.168.10.39:2376 miltitz v1.12.0-rc4 lausen - generic Running tcp://192.168.10.64:2376 v1.12.0-rc4 lindenau - generic Running tcp://192.168.10.66:2376 miltitz v1.12.0-rc4 miltitz - generic Running tcp://192.168.10.65:2376 miltitz (master) v1.12.0-rc4 pirita - generic Running tcp://192.168.10.72:2376 miltitz v1.12.0-rc4 tolkewitz - generic Running tcp://192.168.10.43:2376 miltitz v1.12.0-rc4 tondi - generic Running tcp://192.168.10.73:2376 miltitz v1.12.0-rc4
Der neue Docker Swarm mode
Da die VMs auf insgesamt drei physischen Maschinen verteilt sind, soll auf jedem der Server ein Docker Swarm Manager eingerichtet werden. Den Anfang macht „connewitz“, d.h. die VM, die bislang nur als Client diente. Weitere Hinweise, Parameter etc. befinden sich natürlich in der offiziellen Docker-Dokumentation.
Vorweg sei erwähnt, dass die Einrichtung eines Docker Swarm mit der neuen Version wesentlich einfacher geworden ist. Zwar konnte auch docker-machine einige Komplexität verbergen, indem die für den Swarm-Betrieb notwendigen Parameter übernommen und die Container eingerichtet wurden, aber all dies ist nun nicht mehr notwendig. Ebenfalls lässt sich der neue Docker Swarm mode sehr einfach auf bestehenden Docker Hosts installieren – und noch dazu durchaus sicher, denn die Komplexität bzgl. Zertifikat-Einrichtung und -verwaltung wird genauso von der Docker-Engine selbst übernommen wie die Speicherung der eigentlichen Konfiguration, ein externer Speicher wie Consul oder etcd ist nicht mehr notwendig.
Die Architektur lässt sich wie folgt darstellen:
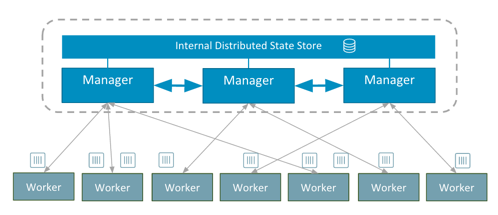
Quelle und Copyright: https://blog.docker.com/2016/06/docker-1-12-built-in-orchestration/
Die Initialisierung auf einem der gewünschten Master (hier: connewitz) geschieht wie folgt:
geschke@connewitz:~$ docker swarm init --listen-addr 192.168.10.60:2377
No --secret provided. Generated random secret:
GENERATEDSECRET
Swarm initialized: current node (9r6mfzv4gflyafi9uwikaaqvf) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --secret GENERATEDSECRET\
--ca-hash sha256:GENERATEDHASH \
192.168.10.60:2377
Das war es auch schon! Weitere Nodes, ob Manager oder nicht, können mit den angegebenen Kommandos und Parametern hinzugefügt werden.
Noch ein kurzer Test:
geschke@connewitz:~$ docker info Containers: 4 Running: 0 Paused: 0 Stopped: 4 Images: 36 Server Version: 1.12.0-rc4 Storage Driver: btrfs Build Version: Btrfs v4.4 Library Version: 101 Logging Driver: json-file Cgroup Driver: cgroupfs Plugins: Volume: local Network: null bridge overlay host Swarm: active NodeID: 9r6mfzv4gflyafi9uwikaaqvf IsManager: Yes Managers: 1 Nodes: 1 [...]
Zeit für einen weiteren Swarm Manager, dieser soll auf „tondi“ installiert werden. In einigen Tutorials und Blog-Einträgen werden diese Schritte ebenfalls beschrieben. Doch entweder es wird sich direkt auf den jeweiligen Docker Hosts eingeloggt, oder docker-machine wird mit dem ssh-Kommando aufgerufen, wie in diesem Beispiel. Da jedoch alle Docker-Kommandos auch per API – und somit per Docker-Client verfügbar sind, müsste es auch anders gehen, schließlich funktioniert die Docker-Engine ja wie zuvor:
docker $(docker-machine config tondi) info [...]
Insofern – wenn normale Kommandos funktionieren, wieso nicht auch die swarm-Konfiguration?
Genau dies ist auch der Fall, somit werden alle weiteren Nodes bzw. Manager wiederum von der Client-Maschine eingerichtet:
geschke@connewitz:~$ docker $(docker-machine config tondi) swarm join --manager --secret GENERATEDSECRET --ca-hash sha256:GENERATEDHASH --listen-addr $(docker-machine ip tondi) 192.168.10.60:2377 Error response from daemon: Your node is in the process of joining the cluster but needs to be accepted by existing cluster member. To accept this node into cluster run "docker node accept 76nj42jlv8ih1lz1yp98juzf7" in an existing cluster manager. Use "docker info" command to see the current Swarm status of your node.
Genau wie gewünscht wurde der neue Swarm Manager eingerichtet, aus Sicherheitsgründen ist jedoch noch eine Bestätigung auf dem bisherigen bzw. ersten Manager notwendig:
geschke@connewitz:~$ docker node accept 76nj42jlv8ih1lz1yp98juzf7 Node 76nj42jlv8ih1lz1yp98juzf7 accepted in the swarm.
Perfekt! Auch das will geprüft werden:
geschke@connewitz:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 76nj42jlv8ih1lz1yp98juzf7 tondi Accepted Ready Active Reachable 9r6mfzv4gflyafi9uwikaaqvf * connewitz Accepted Ready Active Leader
Wie erwartet ist der Host „tondi“ nun als Manager eingerichtet, wobei der aktuelle „Leader“ nach wie vor „connewitz“ ist. Um im Fehlerfall ein eindeutiges Quorum (Docker nutzt den Raft-Algorithmus zur Herstellung von Konsens der Manager-Nodes untereinander) zu erhalten, empfiehlt sich die Nutzung einer ungeraden Anzahl von Manager Nodes, so dass zumindest der Ausfall eines Managers problemlos verkraftet wird. Das Hinzufügen eines weiteren Swarm Managers geschieht analog:
geschke@connewitz:~$ docker $(docker-machine config kaditz) swarm join --manager --secret GENERATEDSECRET --ca-hash sha256:GENERATEDHASH --listen-addr $(docker-machine ip kaditz) 192.168.10.60:2377 Error response from daemon: Your node is in the process of joining the cluster but needs to be accepted by existing cluster member. To accept this node into cluster run "docker node accept 64nf6p2azvujv291ay4g1nhwl" in an existing cluster manager. Use "docker info" command to see the current Swarm status of your node. geschke@connewitz:~$ docker node accept 64nf6p2azvujv291ay4g1nhwl Node 64nf6p2azvujv291ay4g1nhwl accepted in the swarm.
Auch diese Kommandos wurden nur vom „Client“ aus ausgeführt, das Einloggen in weitere VMs ist nicht notwendig. Wie erwartet besteht der Swarm nun aus drei Nodes, die allesamt als Manager fungieren:
geschke@connewitz:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 64nf6p2azvujv291ay4g1nhwl kaditz Accepted Ready Active Reachable 76nj42jlv8ih1lz1yp98juzf7 tondi Accepted Ready Active Reachable 9r6mfzv4gflyafi9uwikaaqvf * connewitz Accepted Ready Active Leader
Alle weiteren Nodes werden als Worker hinzugefügt, etwa die VM „lausen“:
docker $(docker-machine config lausen) swarm join --secret GENERATEDSECRET --ca-hash sha256:GENERATEDHASH --listen-addr $(docker-machine ip lausen) 192.168.10.60:2377 This node joined a Swarm as a worker.
Das Ergebnis ist dieser Swarm Cluster:
geschke@connewitz:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 28v6jjr50etv4sjmx5p4yuhmp lausen Accepted Ready Active 2hwa815cxk6pf8bh4mo7hkx11 tolkewitz Accepted Ready Active 3eg4vn9io09v0046tmuwibsa5 lindenau Accepted Ready Active 64nf6p2azvujv291ay4g1nhwl kaditz Accepted Ready Active Reachable 76nj42jlv8ih1lz1yp98juzf7 tondi Accepted Ready Active Reachable 7yte21jbezc7lwznton64bwi8 pirita Accepted Ready Active 9r6mfzv4gflyafi9uwikaaqvf * connewitz Accepted Ready Active Leader cixviuywhxd6qe2pr2f1u7rwd miltitz Accepted Ready Active
Dabei können alle Kommandos zur Verwaltung des Clusters auch von den aktuell nicht aktiven Manager Nodes ausgeführt werden. Zur Verdeutlichung:
geschke@connewitz:~$ docker $(docker-machine config tondi) node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 28v6jjr50etv4sjmx5p4yuhmp lausen Accepted Ready Active 2hwa815cxk6pf8bh4mo7hkx11 tolkewitz Accepted Ready Active 3eg4vn9io09v0046tmuwibsa5 lindenau Accepted Ready Active 64nf6p2azvujv291ay4g1nhwl kaditz Accepted Ready Active Reachable 76nj42jlv8ih1lz1yp98juzf7 * tondi Accepted Ready Active Reachable 7yte21jbezc7lwznton64bwi8 pirita Accepted Ready Active 9r6mfzv4gflyafi9uwikaaqvf connewitz Accepted Ready Active Leader cixviuywhxd6qe2pr2f1u7rwd miltitz Accepted Ready Active
Der Versuch, die Liste der Nodes von einem Worker aus zu erreichen, endet hingegen wie erwartet in einer Fehlermeldung:
geschke@connewitz:~$ docker $(docker-machine config pirita) node ls Error response from daemon: This node is not a Swarm manager. Worker nodes can't be used to view or modify cluster state. Please run this command on a manager node or promote the current node to a manager.
Jedoch können auch Nodes, die als Worker fungieren, nachträglich als Manager eingerichtet werden.
So viel für heute! Der neue Docker Swarm läuft, nun gilt es, alle weiteren Features zu entdecken, insbesondere die neuen Services und deren Erstellung sowie Skalierung. Immerhin laufen die bisherigen Docker-Container nach wie vor, sofern sie nicht Features des „alten “ Docker Swarm voraussetzen.

