
Vor einiger Zeit waren Pi-Hole und keepalived bereits Thema dieses Blogs. Pi-Hole wurde – mittlerweile eigentlich schon selbstverständlich – als Docker-Container betrieben, keepalived sorgte für die Hochverfügbarkeit, indem es zum einen eine Floating IP bereit stellte, unter der, für die Clients völlig transparent, Pi-Hole auf jeweils einem von zwei Nodes lief und somit bei einem Ausfall einer Maschine weiter betrieben und demzufolge auch genutzt werden konnte.
Wobei Ausfall auch geplante Maßnahmen wie Wartungen oder Updates mit eingeschlossen hat. Neben der Einrichtung der Floating IP sorgte keepalived somit auch dafür, dass Pi-Hole auf demjenigen Host gestartet wurde, auf den die Floating IP gerade zeigte (inzwischen als political incorrect gebrandmarkt, aber aus Gründen der Verständlichkeit nach wie vor MASTER genannt) – und auf dem jeweils anderen ggf. beendet wurde. Dieses Setup lief eine Weile lang erfolgreich, doch mit der Zeit ergaben sich Probleme mit der darunter liegenden Infrastruktur.
Verteilt, veraltet, verschwunden
Denn seinerzeit hatte ich mich für LizardFS als verteiltes Dateisystem entschieden, das auf mehreren VMs im Netz lief und den Speicherplatz für die von Pi-Hole benötigten Dateien bereit stellte. Das LizardFS-Filesystem wurde mittels lfsmount unter Zuhilfenahme des FUSE-Kernel-Moduls in ein Verzeichnis des Hosts gemountet, so dass Pi-Hole auf seine Dateien zugreifen konnte. Dieses Szenario lief durchaus erfolgreich, jedoch wollte ich zumindest die verwendete Ubuntu-Linux-Distribution so aktuell halten, dass die jeweils neueste LTS-Variante zum Einsatz kommt.
Beim Upgrade auf Ubuntu 22.04 LTS zeigte sich, dass sämtliche Pakete, die zu LizardFS gehörten, aus der Distribution verschwunden waren. Nach einem näherer Blick auf die Web- und GitHub-Seiten von LizardFS wurde auch der Grund schnell klar – die Weiterentwicklung scheint eingeschlafen zu sein, das letzte Release ist datiert auf Dezember 2017, und die letzten Änderungen im Repository sind mittlerweile fast zwei Jahre alt. Das alles wäre nun nicht so schlimm, schließlich muss stabil laufende Software nicht zwangsläufig permanent aktualisiert werden, doch inzwischen wurde aus dem Umfeld der Autoren die Aussage getroffen, dass die Open-Source-Variante von Lizardfs nicht mehr weiterentwickelt wird. Insofern wurde es Zeit, sich nach einer Alternative umzusehen.
DRBD – Daten Rauf, Backup Da!
Dafür geeignet erschien mir DRBD (Distributed Replicated Block Device), eine Open-Source-Lösung zur Spiegelung von Daten in Echtzeit über mehrere Server hinweg. Dabei wird die Hochverfügbarkeit durch Replizierung der Daten auf Blockebene hergestellt, so dass bei Ausfall eines Servers immer eine Kopie verfügbar ist.
Die einfachste Konfiguration ist mittels zweier Server möglich, man kann sich dies als eine Art RAID-1 übers Netzwerk vorstellen. DRBD integriert sich nahtlos in bestehende Linux-Systeme, Ausfallzeiten werden minimiert, DRBD sorgt dabei für Integrität der Daten im Failover-Fall. DRBD ist inzwischen Teil des Linux-Kernels, bietet eine große Community und wird auch im kommerziellen Rahmen gepflegt und durch weitere Produkte ergänzt, so dass zumindest eine hohe Wahrscheinlichkeit besteht, dass das Projekt auch weiterhin und vor allem längerfristig Bestand haben wird.
Auf die weiteren Fähigkeiten, insbesondere von DRBD 9, werde ich hier nicht weiter eingehen, ebenso wenig auf die Performance-Unterschiede zu einem verteilten Dateisystem. Grundsätzlich ging es mir darum, die von Pi-Hole beim Betrieb notwendigen bzw. ebenso die erzeugten Daten wie Logs, bei Ausfall eines Hosts weiterhin nutzen zu können, oder etwa auch bei Unterbrechung angesichts Updates o.ä..
Skizze: DRBD, DNS, Pi-Hole im Normalbetrieb
Zur genauen Vorstellung der gewünschten Konfiguration sollen folgende Visualisierungen dienen. Zunächst eine Übersicht des normalen Betriebs:
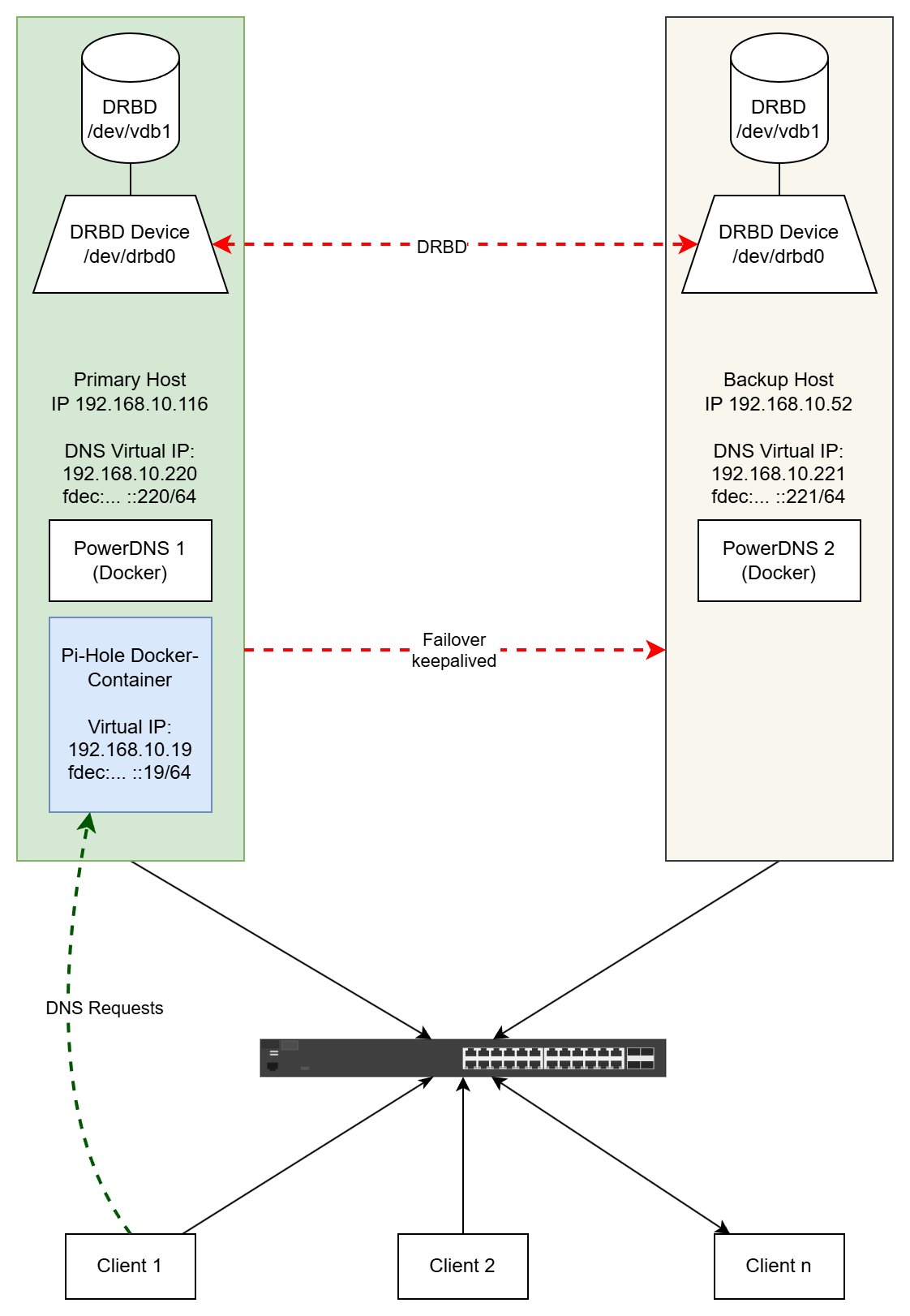
Auf den beiden hier dargestellten Servern bzw. VMs laufen mehrere Dienste. Da wären zunächst PowerDNS als DNS-Server, analog zur bereits vor einiger Zeit beschriebenen Lösung. Der primäre DNS, genannt nsintern1 nimmt auf dem primären Host Platz, der sekundäre namens nsintern2 auf der hier als Backup Host bezeichneten Maschine. DRBD fungiert als Dienst auf beiden Hosts, beide VMs haben jeweils ein 100 GB große Partition /dev/vdb1, woraus das ebenfalls 100 GB große DRBD-Laufwerk (oder auch „Ressource“) /dev/drbd0 wird. Dabei ist das Dateisystem des DRBD-Laufwerks nur auf dem primären Host gemountet, so dass darauf lesender und schreibender Zugriff erfolgen kann, während die Ressource auf dem Backup Host nur Updates vom primären System empfängt und für die permanente Replikation sorgt. Pi-Hole greift somit auf das Dateisystem der DRBD-Ressource des primären Hosts zu.
Im Normalbetrieb nimmt der Pi-Hole-Container auf dem primären Host alle DNS-Anfragen entgegen, hier am Beispiel von „Client 1“ dargestellt.
Skizze: Pi-Hole im Failover-Fall
Den Failover-Fall zeigt folgendes Diagramm:
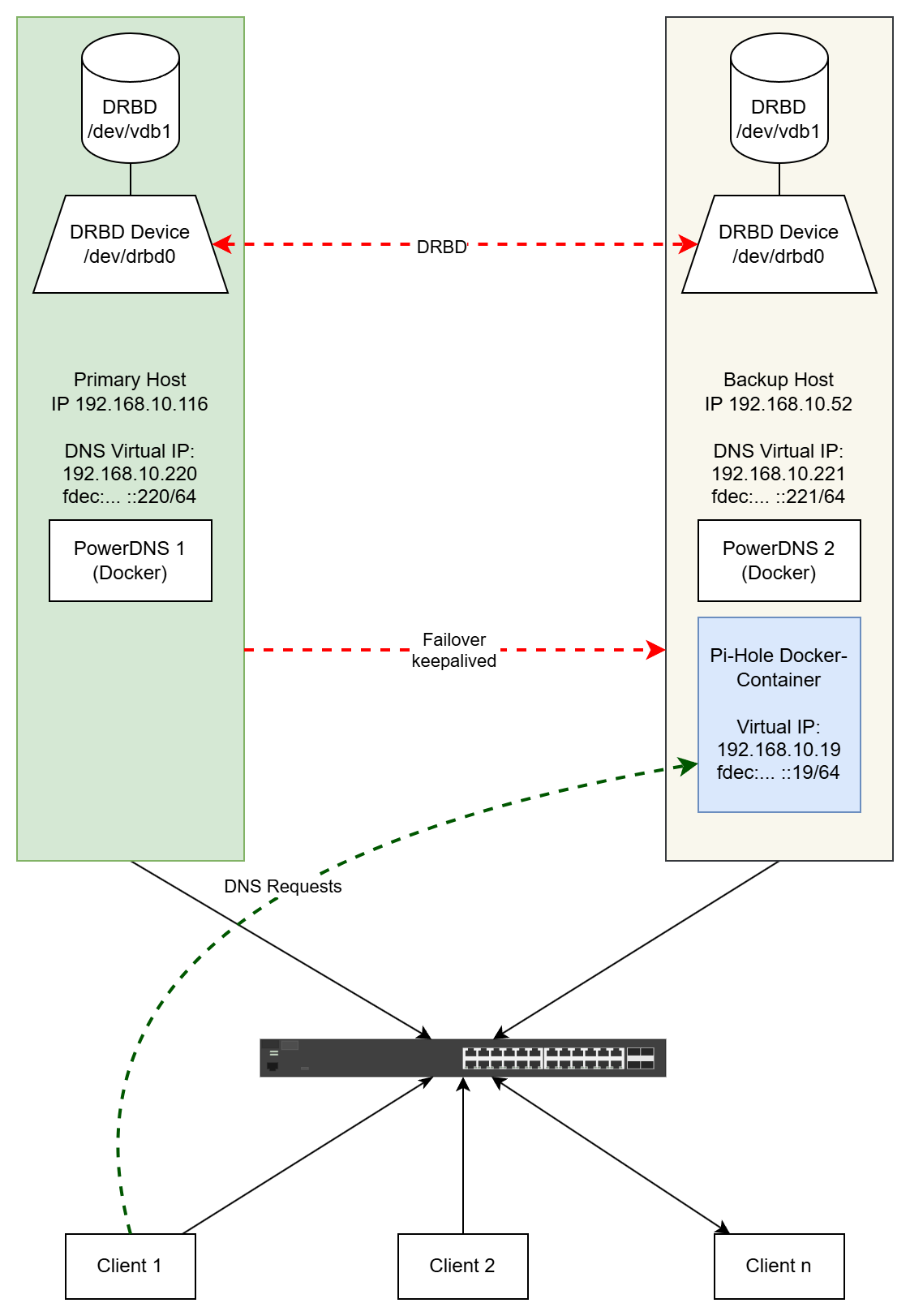
Sobald keepalived einen Ausfall des primären Hosts bemerkt, wird zunächst DRBD dazu angewiesen, die DRBD-Ressource auf dem Backup Host zu mounten, d.h. es wird selbst zum primären System, so dass lesender wie schreibender Zugriff möglich ist. Daraufhin wird auf dem Backup Host wiederum Pi-Hole gestartet, das dank DRBD auf dieselben Daten zugreifen kann. Ebenfalls sorgt keepalived dafür, dass die IP-Adressen von Pi-Hole, dies betrifft sowohl IPv4 als auch IPv6, vom Backup Host übernommen werden.
Da diese Vorgänge automatisiert erfolgen und insgesamt in auf meinen Systemen in durchschnittlich 10 – 15 Sekunden abgeschlossen sind (DRBD-Rollentausch: weniger als zwei Sekunden, Mounten des Dateisystems: ca. zwei Sekunden, Start von Pi-Hole: unter 10 Sekunden), ist eine solche Unterbrechung für ein Heimnetz meiner Ansicht nach absolut akzeptabel, bzw. mitunter wird man als Anwender gar nichts davon merken.
Alle DNS-Requests der Clients erfolgen im Failover-Fall auf dem Backup Host. Da die DNS-Server auf beiden VMs laufen, ist dabei bereits ausreichend Redundanz gegeben. Sobald der primäre Host wieder in Betrieb ist, sorgt keepalived dafür, dass der vorherige Zustand wiederhergestellt wird.
Erste Schritte mit DRBD
Da ich die Installation bereits vor geraumer Zeit vorgenommen habe, werde ich hier nur kurz darauf eingehen, darüber hinaus existieren dafür sehr viele Anleitungen, z.B. in der Ubuntu-Server-Dokumentation. Nach der obligatorischen Installation von Linux genügt ein sudo apt install drbd-utils, um DRBD zu installieren.
Da Ubuntu nicht direkt eine Datei /etc/drbd.conf zur Konfiguration verwendet, sondern deren Inhalte nur auf andere Dateien verweisen bzw. alle Dateien mit der Endung „.res“ aus dem Verzeichnis /etc/drbd.d/ einbinden, und ich mich durchaus gerne an Konventionen der Distribution halte, habe ich eine Datei /etc/drbd.d/drbd.res zur eigentlichen Konfiguration verwendet. Der Inhalt bleibt dabei identisch zur Datei drbd.conf, die in der Ubuntu-Dokumentation genannt wird. Für meine Systeme sieht die aktuelle Konfiguration so aus:
global { usage-count no; }
common { syncer { rate 100M; } }
resource r0 {
protocol C;
startup {
wfc-timeout 15;
degr-wfc-timeout 60;
}
net {
cram-hmac-alg sha1;
shared-secret "ganz_geheimes_gemeinsames_wort";
}
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
}
on marzahn {
device /dev/drbd0;
disk /dev/vdb1;
address 192.168.10.116:7788;
meta-disk internal;
}
on gruenau {
device /dev/drbd0;
disk /dev/vdb1;
address 192.168.10.52:7788;
meta-disk internal;
}
}
Die Inhalte sind beinahe selbsterklärend. Anstatt die beteiligten VMs durchzunummerieren, habe ich deren Hostnamen marzahn und gruenau verwendet. Die IP-Adressen sind ebenfalls enthalten, außerdem die bereits erwähnte, 100 GB große Partition /dev/vdb1, die zum DRBD-Laufwerk bzw. der Ressource /dev/drbd0 wird. Diese Ressource wird als „r0“ definiert und unter diesem Namen auch im Betrieb angesprochen. Der Rest ist aus dem Beispiel übernommen, dabei sind die Angaben in den „handlers“ optional, es handelt sich um Skripte, die zur Information dienen, sobald ein Fehler auftaucht.
Da keine Host-spezifischen Angaben enthalten sind, kann die Datei einfach auf die zweite Maschine kopiert und ebenfalls in das Verzeichnis /etc/drbd.d/ platziert werden.
Danach wird der so genannte Meta Data Storage eingerichtet, ein Bereich, in dem DRBD Verwaltungsdaten speichert, z.B. Synchronisationsstatus und Rollen (primary/secondary) der Nodes. Zwar könnte dieser auch in einer separaten Partition Platz finden, der Einfachheit halber habe ich jedoch die inline-Variante, d.h. die direkte Speicherung auf der Festplatte gewählt:
geschke@marzahn:/etc/drbd.d$ sudo drbdadm create-md r0 initializing activity log initializing bitmap (3200 KB) to all zero Writing meta data... New drbd meta data block successfully created.
Genau dasselbe muss auf der zweiten Maschine erfolgen, denn noch sind die Nodes nicht miteinander verbunden.
Anschließend wird der Service DRBD gestartet, und zwar wiederum auf beiden Maschinen:
geschke@marzahn:/etc/drbd.d$ sudo systemctl start drbd.service
geschke@marzahn:/etc/drbd.d$ sudo systemctl status drbd.service
● drbd.service - DRBD -- please disable. Unless you are NOT using a cluster manager.
Loaded: loaded (/lib/systemd/system/drbd.service; disabled; vendor preset: enabled)
Active: active (exited) since Sun 2022-11-20 19:27:51 UTC; 9s ago
Process: 2763 ExecStart=/lib/drbd/drbd start (code=exited, status=0/SUCCESS)
Main PID: 2763 (code=exited, status=0/SUCCESS)
CPU: 136ms
Nov 20 19:27:40 marzahn drbd[2771]: adjust disk: r0
Nov 20 19:27:40 marzahn drbd[2771]: adjust net: r0
Nov 20 19:27:40 marzahn drbd[2771]: ]
Nov 20 19:27:40 marzahn drbd[2795]: WARN: stdin/stdout is not a TTY; using /dev/console
Nov 20 19:27:40 marzahn drbd[2798]: degr-wfc-timeout has to be shorter than wfc-timeout
Nov 20 19:27:40 marzahn drbd[2798]: degr-wfc-timeout implicitly set to wfc-timeout (15s)
Nov 20 19:27:40 marzahn drbd[2798]: outdated-wfc-timeout has to be shorter than degr-wfc-timeout
Nov 20 19:27:40 marzahn drbd[2798]: outdated-wfc-timeout implicitly set to degr-wfc-timeout (15s)
Nov 20 19:27:51 marzahn drbd[2763]: ...done.
Nov 20 19:27:51 marzahn systemd[1]: Finished DRBD -- please disable. Unless you are NOT using a cluster manager..
Die Status-Ausgabe empfand ich zunächst als ein wenig verwirrend, von wegen man möge den DRBD-Service doch bitte deaktivieren, falls kein Cluster-Manager Verwendung findet. Aber genau ein solcher, und zwar in Form von keepalived, wird im weiteren Verlauf eingerichtet, insofern ignorieren wir die Warnung einfach mal.
Spannender wurde es bei der Initialisierung des DRBD-Laufwerks. Dazu wurde folgendes Kommando auf dem Host aufgerufen, der als primärer Host dienen soll, in meinem Fall handelte es sich um „marzahn“, insofern:
geschke@marzahn:/etc/drbd.d$ sudo drbdadm -- --overwrite-data-of-peer primary all
Um den aktuellen Status der Replikation zu beobachten, habe ich auf dem zweiten Node mit dem Kommando watch -n1 cat /proc/drbd Ausgaben erhalten wie diese:
Every 1.0s: cat /proc/drbd marzahn: Sun Nov 20 19:30:19 2022
version: 8.4.11 (api:1/proto:86-101)
srcversion: F1B419ECD3D00AF78F2375D
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:2019328 nr:0 dw:0 dr:2021448 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:102832988
[>....................] sync'ed: 2.0% (100420/102392)M
finish: 0:44:19 speed: 38,656 (38,100) K/sec
Und tatsächlich dauerte die vollständige Replikation und damit Einrichtung eine ganze Weile. Zugegebenermaßen hatte ich den Speicherplatz aber auch sehr großzügig gewählt, nach mittlerweile über zwei Jahren Betrieb sind im DRBD-Laufwerk von den 100 verfügbaren GB gerade mal drei belegt.
Nach Fertigstellung zeigte sich ein gewisser Erfolg in der Ausgabe:
geschke@marzahn:/etc/drbd.d$ cat /proc/drbd
version: 8.4.11 (api:1/proto:86-101)
srcversion: F1B419ECD3D00AF78F2375D
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:104852316 nr:0 dw:0 dr:104854436 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
Das DRBD-Laufwerk stand auf dem primären Node zur Verfügung und musste nun noch mit einem Filesystem bestückt werden, für XFS beispielsweise mittels sudo mkfs.xfs /dev/drbd0. Nach Abschluss habe ich noch einen Mountpoint für die DRBD-Ressource angelegt, hierfür erschien mir /vol/drbd geeignet, insofern sudo mkdir -p /vol/drbd.
Nach dem Mounten auf dem primären Host (sudo mount /dev/drbd0 /vol/drbd) stand der Speicherplatz zur Verfügung und konnte genutzt werden.
geschke@marzahn:/$ df -h Filesystem Size Used Avail Use% Mounted on tmpfs 795M 1.1M 794M 1% /run /dev/vda3 148G 7.8G 141G 6% / tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/vda2 2.0G 127M 1.7G 7% /boot tmpfs 795M 4.0K 795M 1% /run/user/1000 /dev/drbd0 100G 746M 100G 1% /vol/drbd
Um die Funktionalität der Replikation zu testen, habe ich zunächst einige Dateien in das DRBD-Verzeichnis kopiert. Anschließend folgte ein manueller, etwas aufwändiger Vorgang, doch genau diese Schritte werden im späteren Betrieb von keepalived erledigt. Denn im Gegensatz zum früher verwendeten verteilten Dateisystem sind bei DRBD die Rollen klar getrennt – nur der als Primary deklarierte Host, in diesem Fall marzahn, erhält schreibenden sowie lesenden Zugriff, während die Secondary Rolle ausschließlich Updates empfängt.
Um auf der zweiten Maschine Zugriff auf das DRBD-Laufwerk zu erhalten, muss zunächst auf dem Primary das Laufwerk unmountet werden, anschließend wird der Primary zum Secondary erklärt, und auf dem Secondary Server erfolgt wiederum dessen Einrichtung als Primary. Danach kann das DRBD-Laufwerk auf dem Secondary gemountet werden. Die Schritte zusammengefasst, zunächst auf dem Primary Host inkl. Status-Ausgabe:
geschke@marzahn:/$ sudo umount /vol/drbd
geschke@marzahn:/$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 795M 1.1M 794M 1% /run
/dev/vda3 148G 7.8G 141G 6% /
tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 2.0G 127M 1.7G 7% /boot
tmpfs 795M 4.0K 795M 1% /run/user/1000
geschke@marzahn:/$ sudo drbdadm secondary r0
geschke@marzahn:/$ cat /proc/drbd
version: 8.4.11 (api:1/proto:86-101)
srcversion: F1B419ECD3D00AF78F2375D
0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r-----
ns:104854975 nr:0 dw:104906171 dr:104856718 al:415 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
Auf dem Secondary Host sieht es dann wie folgt aus:
geschke@gruenau:/etc/drbd.d$ sudo drbdadm primary r0
geschke@gruenau:/etc/drbd.d$ cat /proc/drbd
version: 8.4.11 (api:1/proto:86-101)
srcversion: F1B419ECD3D00AF78F2375D
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:0 nr:104854975 dw:209758487 dr:232 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
geschke@gruenau:/etc/drbd.d$ sudo mount /dev/drbd0 /vol/drbd/
geschke@gruenau:/etc/drbd.d$ cd /vol/drbd/
Danach stehen die Testdaten, die zuvor vom Primary in das DRBD-Laufwerk kopiert wurden, auch auf dem Secondary zur Verfügung. Wobei der frühere Secondary ja nun seines Zeichens zum Primary geworden ist… Aber ich denke, die Funktionsweise dürfte klar geworden sein. Um wieder den Host marzahn als Primary zu deklarieren, sind die Schritte einfach umgekehrt auszuführen. Im Folgenden wird davon ausgegangen, dass marzahn über die Primary-Rolle verfügt, während der Host gruenau wieder der Secondary ist.
Ah, ha, ha, ha, stayin‘ alive, äh… keepalived!
Da DRBD nun erfolgreich installiert wurde, ist es an der Zeit, sich darum zu kümmern, dass die oben beschriebenen Schritte bei einem Ausfall automatisiert ausgeführt werden können. Dafür habe ich keepalived eingesetzt, eine Open-Source-Software, die primär für die Verwaltung von Hochverfügbarkeit (High Availability, HA) in Netzwerken entwickelt wurde. Keepalived überwacht den Status von Servern oder Diensten und sorgt bei einem Ausfall dafür, dass ein Backup-System nahtlos die Aufgaben des primären Systems übernimmt. Dies geschieht durch die Nutzung des Virtual Router Redundancy Protocol (VRRP), das IP-Adressen dynamisch zwischen Hosts verschieben kann. Im hier dargestellten Szenario sorgt keepalived nicht nur für die Umsetzung der IP-Adresse, sondern ist auch für DRBD und Pi-Hole zuständig, so dass diese Dienste vom Backup-System übernommen bzw. darauf gestartet werden.
Während die eigentliche Installation von keepalived noch einfach erscheint, sind die Möglichkeiten der Konfiguration sehr vielfältig. Letztlich habe ich nicht nur Zeit mit Trial-and-Error verbracht, außerdem so einige Iterationsschritte benötigt, bis keepalived so eingerichtet war, dass all meine Anforderungen erfüllt waren. Geholfen haben dabei viele, also wirklich, wirklich viele Blog-Beiträge, Foren, Web-Seiten mit Hinweisen, Skripten etc., die ich gar nicht alle nennen kann. Letztlich handelt es sich bei der aktuellen Konfiguration um die Quintessenz all jener Beiträge, ergänzt durch eigene Funktionen, respektive Skripte. Da dieser Beitrag bereits eine gewisse Länge hat, werde ich in diesem Teil nur die grundlegende Installation und Konfiguration von keepalived ausführen, und in einem zweiten Teil auf den aktuellen Stand eingehen. Darin werden dann auch alle Skripte und sonstige Konfigurationsdateien enthalten sein, der nächste Beitrag wird somit sehr viel Quellcode beinhalten.
keepalived und der Kernel
Damit keepalived die IP-Adresse umsetzen kann, muss zunächst die Einstellung ip_nonlocal_bind in den Kernel-Parametern auf 1 gesetzt, d.h. aktiviert werden. Die nachfolgenden Beispiele beziehen sich zunächst auf IPv4, deren aktuelle Konfiguration unter /proc/sys/net/ipv4/ip_nonlocal_bind zu finden ist. Diese Angabe kann wie folgt ausgelesen werden:
geschke@marzahn:/$ cat /proc/sys/net/ipv4/ip_nonlocal_bind 0
Eine 0 bedeutet, dass die Option nicht aktiv ist, weshalb eine Aktivierung vonnöten ist. Um nicht die zentrale Datei /etc/sysctl.conf ändern zu müssen oder mit anderen Konfigurationsdateien nicht in Konflikt zu kommen, habe ich auf beiden Hosts eine Datei /etc/sysctl.d/20-keepalived.conf mit dem folgenden Inhalt angelegt:
net.ipv4.ip_nonlocal_bind = 1
Falls der Aufruf von sudo sysctl -p /etc/sysctl.d/20-keepalived.conf nicht zum Erfolg führt, d.h. die Änderungen nicht aktiviert wurden, empfiehlt es sich, die Hosts einmal neu zu booten und dann die Einstellung nochmal zu kontrollieren. Beim Start des Systems werden alle *.conf-Dateien im Verzeichnis /etc/sysctl.d/ der Reihenfolge ihres Namens nach eingelesen und die Parameter entsprechend gesetzt.
keepalived: Installation und Konfiguration
Damit sind die Vorbereitungen abgeschlossen, und keepalived kann auf beiden Systemen installiert werden:
geschke@marzahn:~$ sudo apt install -y keepalived
Die zentrale Konfigurationsdatei für keepalived befindet sich in /etc/keepalived, evtl. wurde auch eine /etc/keepalived/keepalived.conf.sample angelegt, die zumindest auf meinem System etwas länger geraten ist. Ohne die Datei /etc/keepalived/keepalived.conf ist keepalived jedenfalls zu keiner sinnvollen Aktion zu überreden. Im Gegensatz zu DRBD unterscheiden sich die Konfigurationsdateien auf dem primären und dem sekundären System, insofern zunächst ein Beispiel für den primären Host, sowohl in der offiziellen Dokumentation als auch hier nach wie vor Master genannt:
vrrp_instance VI_1 {
state MASTER
interface ens3 # Beispiel: eth0
virtual_router_id 51 # Eine eindeutige ID für die VRRP-Instanz
priority 100 # Höhere Priorität für den Primary Node
advert_int 1 # Intervall für Heartbeats (in Sekunden)
authentication {
auth_type PASS
auth_pass 12345 # Passwort für die Authentifizierung
}
virtual_ipaddress {
192.168.10.19/24 # Die Virtual IP Address
}
}
Die Konfiguration auf dem Secondary Host ist nahezu identisch, nur mit einem anderer Einstellung für den Status (state, relevant im späteren Betrieb) und einer niedrigeren Priorität versehen:
vrrp_instance VI_1 {
state BACKUP
interface ens3 # Beispiel: eth0
virtual_router_id 51
priority 90 # Niedrigere Priorität für den Secondary Node
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.10.19/24
}
}
keepalived: Start und Test
Anschließend kann keepalived auf beiden Hosts aktiviert und gestartet werden:
$ sudo systemctl enable keepalived.service $ sudo systemctl start keepalived.service
Die virtuelle IP-Adresse sollte daraufhin auf den primären Host gesetzt worden sein, zur Überprüfung entweder ip a ausführen, alternativ lässt sich die Ausgabe ein wenig eingrenzen:
geschke@marzahn:/etc/keepalived$ ip -4 a show ens3
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
altname enp0s3
inet 192.168.10.116/24 brd 192.168.10.255 scope global ens3
valid_lft forever preferred_lft forever
inet 192.168.10.20/24 brd 192.168.10.255 scope global secondary ens3
valid_lft forever preferred_lft forever
inet 192.168.10.220/24 brd 192.168.10.255 scope global secondary ens3
valid_lft forever preferred_lft forever
inet 192.168.10.19/24 scope global secondary ens3
valid_lft forever preferred_lft forever
Neben den fest bzw. per DHCP vergebenen IPv4-Adressen hat dieser Node somit die virtuelle IP-Adresse erhalten und ist darunter auch erreichbar. Zum Test des Failovers kann keepalived auf dem primären Host heruntergefahren werden:
geschke@marzahn:/etc/keepalived$ sudo systemctl stop keepalived
Nach kurzer Zeit sollte die IP-Adresse vom zweiten Host übernommen worden sein. Nach erneutem Start von keepalived auf dem Master wird die IP-Adresse erneut auf das primäre System verschoben. Falls all dies nicht funktioniert, hilft ein Blick ins Syslog, denn keepalived ist durchaus gesprächig, was seine Aktivitäten anbetrifft.
Die offizielle Dokumentation von keepalived ist zwar einigermaßen ausführlich, aber meiner Ansicht nach eher etwas für Hartgesottene. Letztlich handelt es sich um die Manpage für keepalived.conf, die ebenfalls mittels man keepalived.conf erreichbar ist. Hier lohnt sich also das Erschließen weiterer Quellen.
Am Ende wird alles gut, aber das ist noch nicht das Ende!
Damit sind die Vorbereitungen für den angestrebten Betrieb von Pi-Hole zunächst einmal abgeschlossen. Der Betrieb von Pi-Hole wird mittels Docker-Container realisiert, ähnlich wie bereits beschrieben. Der zweite Teil beschäftigt sich dann mit der Konfiguration von keepalived in Verbindung mit den benutzerdefinierten Skripten, wobei ich meine aktuell laufende Fassung zeigen werden. Für Kommentare, Hinweise auf Fehler, Optimierungen etc. bin ich wie immer dankbar.


 im Heimnetz mit pfSense")
