
Wie bereits im ersten Artikel angekündigt, soll es in diesem Beitrag um die konkrete Konfiguration von Keepalived und insbesondere um die damit einher gehenden Skripte gehen, die dafür sorgen, dass im Failover-Fall die DRBD-Ressource auf den Secondary Host gelangt, auf dem – nun in der Primary-Rolle – zu guter Letzt Pi-Hole gestartet wird.
Konfiguration von Keepalived
Zunächst zur eigentlichen Konfigurationsdatei von Keepalived, die sich im Verzeichnis /etc/keepalived/ befindet. Auf dem primären Host, d.h. dem Master sieht die keepalived.conf wie folgt aus:
global_defs {
notification_email {
meine-email-adresse@example.com # Benachrichtigungs Zieladresse(n)
}
notification_email_from keepalived@example.com # Benachrichtigungs Quelladresse
smtp_server mailout.example.com # SMTP Serveradresse
smtp_connect_timeout 30 # Timeout zum SMTP Server
router_id marzahn # Eindeutige ID wie z.B. HOSTNAME
script_user root # Benutzer der Notify Scripte
enable_script_security
shutdown_script /etc/keepalived/shutdown.sh
shutdown_script_timeout 20
max_auto_priority -1 # disables startup warning
}
vrrp_script chk_pihole {
script "/etc/keepalived/check_pihole.sh"
interval 20
timeout 45
fall 6
rise 5 # was: 10
#weight 12
}
vrrp_instance drbddns {
state MASTER
interface ens3 # Genutztes Interface
virtual_router_id 100 # ID der Route, willkuerlich
priority 150 # Master Prio 150, Backup Prio 50
advert_int 5 # Intervall der VRRP Pakete
smtp_alert # E-Mail Benachrichtigung aktiviren
#notify /etc/keepalived/notify_stop.sh
notify /etc/keepalived/notify.sh
#debug
nopreempt
unicast_src_ip 192.168.10.116 # Unicast Quelladresse
unicast_peer {
192.168.10.52 # Unicast Zieladresse(n)
}
virtual_ipaddress {
192.168.10.19/24 # Virtuelle Failover IP-Adresse
}
virtual_ipaddress_excluded {
fdec:e179:117a::19/64
}
track_script {
chk_pihole
}
}
Auf dem Secondary- bzw. Backup-Host lautet das Pendant:
global_defs {
notification_email {
meine-email-adresse@example.com # Benachrichtigungs Zieladresse(n)
}
notification_email_from keepalived@example.com # Benachrichtigungs Quelladresse
smtp_server mailout.example.com # SMTP Serveradresse
smtp_connect_timeout 30 # Timeout zum SMTP Server
router_id gruenau # Eindeutige ID wie z.B. HOSTNAME
script_user root # Benutzer der Notify Scripte
enable_script_security
shutdown_script /etc/keepalived/shutdown.sh
shutdown_script_timeout 20
max_auto_priority -1 # disables startup warning
}
vrrp_script chk_pihole {
script "/etc/keepalived/check_pihole.sh"
interval 20
timeout 45
fall 6
rise 10
#weight 12
}
vrrp_instance drbddns {
state BACKUP
interface ens3 # Genutztes Interface
virtual_router_id 100 # ID der Route, willkuerlich
priority 50 # Master Prio 150, Backup Prio 50
advert_int 5 # Intervall der VRRP Pakete
smtp_alert # E-Mail Benachrichtigung aktiviren
notify /etc/keepalived/notify.sh
unicast_src_ip 192.168.10.52 # Unicast Quelladresse
unicast_peer {
192.168.10.116 # Unicast Zieladresse(n)
}
virtual_ipaddress {
192.168.10.19/24 # Virtuelle Failover IP-Adresse
}
virtual_ipaddress_excluded {
fdec:e179:117a::19/64
}
track_script {
chk_pihole
}
}
Bis auf die E-Mail-Adressen bzw. die dafür verwendeten Domains entsprechen diese Dateien der aktuellen Konfiguration auf meinen Systemen.
keepalived.conf im Detail
Gegenüber dem Beispiel aus dem letzten Artikel gibt es einige Unterschiede, auf die ich im Folgenden näher eingehen möchte.
Zunächst einmal gibt es einen Bereich „global_defs“ , in dem einige globale Optionen gesetzt werden. Auch wenn hier nicht verwendet, so ist es möglich, mehrere vrrp_instance-Abschnitte zu nutzen, z.B. um verschiedene Virtual-IPs oder verschiedene Dienste mit unterschiedlichen Failover-Regeln zu definieren. Die Mail- und Mailserver-Einstellungen dürften selbsterklärend sein, daneben wird die router_id auf den Namen des jeweiligen Hosts gesetzt. Darüber hinaus befindet sich bereits ein erster Hinweis auf ein Skript, dazu später mehr.
Es folgt die Definition eines Skripts im Bereich „vrrp_script“ . Das Skript erhält den Namen „chk_pihole“ und kann darunter angesprochen werden, dies passiert im letzten Abschnitt mittels „track_script„. An dieser Stelle werden Parameter definiert, die die Ausführung näher spezifizieren, z.B. den Pfad im Dateisystem zum (Bash-)Skript, die Ausführung in einem Intervall von 20 Sekunden, oder den Timeout.
Mittels „fall“ wird die Anzahl Skript-Läufe festgelegt, bei denen es zu Fehlern kommen kann. Wenn das Skript in dieser Konfiguration sechs Mal fehlschlägt, wird die Priorität reduziert, was letztlich bedeutet, dass der Backup-Host übernimmt.
Die Angabe in „rise“ hingegen bestimmt den umgekehrten Fall, d.h. wenn das Skript wieder jene Anzahl in Folge erfolgreich ist, erhält die Instanz wieder die Master-Rolle. Ich habe die Anzahl sowohl in „fall„, als auch in „rise“ recht hoch gesetzt, da der Start von Pi-Hole schon mal etwas länger dauern kann, z.B. bei einem Upgrade, wenn die Docker-Images erst noch heruntergeladen werden müssen, bevor sie gestartet werden können.
Außerdem dauert der Start selbst auch schon einmal einige Sekunden. Es wäre eher suboptimal, wenn in einem solchen Fall versucht werden würde, Pi-Hole auf dem sekundären Host zu starten, was dann ggf. auch länger dauern würde usw.. Tatsächlich war hier einiges Ausprobieren notwendig, zu kurze Angaben könnten zu einem „Flattern“ (flapping) führen, d.h. ein einzelner Fehler bzw. Erfolg führt zu einem Wechsel von Master und Backup, und umgekehrt.
Darunter wird die eigentliche VRRP-Instanz konfiguriert, die ausnahmsweise nicht durchnummeriert wurde, sondern den Namen „drbddns“ erhält. Es folgt das Setzen des state MASTER bzw. BACKUP, das verwendete Interface ist auf beiden virtuellen Maschinen identisch, als „virtual_router_id“ hatte ich mir die 100 ausgesucht, da in sämtlichen Beispielen aus irgendwelchen Gründen immer eine Zahl 51 angegeben war, und ich davon einfach mal abweichen wollte.
Wichtig ist das Setzen der Priorität mittels „priority“ , dabei gilt, dass der primäre Host auch die höhere Zahl erhalten muss. Als Intervall für die Heartbeat-Nachrichten in „advert_int“ (VRRP-Advertisements) erschien mir 5 Sekunden ausreichend. Dabei sendet der Master regelmäßig VRRP-Advertisements, um anzuzeigen, dass er noch aktiv ist. Der Backup-Host prüft wiederum, ob er innerhalb dieses Intervalls Nachrichten erhält. Falls nicht, übernimmt er die Rolle des Masters.
Es folgt wiederum ein Verweis auf ein Skript, diesmal handelt es sich um „notify“ . Dabei wird das zentrale Verwaltungs- und Steuerungs-Skript aufgerufen, wenn ein bestimmtes Ereignis in in einer „vrrp_instance“ eintritt. Auch dies wird im weiteren Verlauf näher erläutert.
Darunter werden mittels „unicast_src_ip“ und „unicast_peer“ zunächst die eigene IP-Adresse sowie die IP-Adresse des jeweils anderen Hosts definiert. Diese Unicast-Adressierung unterscheidet sich von der im Beispiel verwendeten Multicast-Adressierung, die Keepalived standardmäßig verwendet. Die VRRP-Nachrichten werden hier nicht an alle Adressen im Netz, sondern nur an den jeweils anderen Host versendet. Demgegenüber fehlt der Abschnitt „authentication“ . Die Authentifizierung ist nicht zwingend notwendig, und da das Heimnetzwerk eine isolierte Umgebung darstellt, wird es kaum ein externes Gerät geben, das sich als VRRP-Teilnehmer ausgibt. Außerdem sprechen die Hosts dank Unicast nur direkt miteinander. In produktiven Umgebungen, die eine höhere Anforderung an die Sicherheit stellen, wäre der Authentifizierungs-Abschnitt hingegen empfehlenswert.
Das Setzen der virtuellen IPv4-Adresse mittels „virtual_ipaddress“ sollte aus dem letzten Artikel bekannt sein, dabei handelt es sich um die virtuelle Adresse, die in den VRRP-Adverts, d.h. den regelmäßigen Heartbeat-Nachrichten, versendet und somit übernommen wird. Der Bereich „virtual_ipaddress_excluded“ ist auf den ersten Blick vielleicht etwas missverständlich. Darin enthalten ist die IPv6-Adresse, die zwar vom Backup-Host im Failover-Fall übernommen wird, jedoch wird diese nicht in den VRRP-Adverts versendet. Grundsätzlich dient der Abschnitt dazu, die Größe von VRRP-Adverts bei vielen IP-Adressen zu reduzieren, spezifische Adressen auszuschließen oder eben – wie hier geschehen – gemischte IPv4- und IPv6-Umgebungen zu konfigurieren, da alle Adressen im Bereich „virtual_ipaddress“ zu derselben Adressfamilie gehören müssen.
Analog zu IPv4 muss auch für IPv6 zunächst der Kernel-Parameter gesetzt werden, bei meinen Hosts befinden sich daher beide Einstellungen in der Datei /etc/sysctl.d/20-keepalived.conf:
net.ipv4.ip_nonlocal_bind = 1 net.ipv6.ip_nonlocal_bind = 1
Die Nutzung von „virtual_ipaddress_excluded“ erklärt sich dadurch, dass ansonsten zwei VRRP-Instanzen verwendet werden müssten, wobei es zu Konflikten kommen könnte, z.B. wenn sich eine Instanz bereits im Failover-Fall befindet, während die andere noch nicht umgeschaltet worden ist. Die Nutzung nur einer VRRP-Instanz sorgt hingegen dafür, dass IPv4 und IPv6 synchron bleiben und ist somit weniger fehleranfällig.
Zum Schluss wird die Direktive „track_script“ verwendet, um das bereits definierte Skript mit dem Namen „chk_pihole“ regelmäßig auszuführen. Der Erfolgs- bzw. Fehlerfall wird durch die Rückgabewerte definiert, gibt das Skript den Wert 0 zurück, bedeutet das, dass alles in Ordnung ist, der Dienst ist verfügbar. Ein Wert ungleich 0 hingegen signalisiert den Fehlerfall, d.h. der Dienst, hier wäre dies Pi-Hole, ist ausgefallen, die Priorität wird reduziert und der Failover initiiert. Hier sorgt „track_script“ somit dafür, dass nicht nur der Ausfall des Hosts bemerkt wird, sondern auch ein Ausfall des darauf befindlichen Dienstes Pi-Hole.
Neben den hier dargestellten Direktiven existieren noch gefühlt Myriaden weitere, die eine sehr flexible Konfiguration ermöglichen. Keepalived ist insgesamt ein sehr mächtiges Werkzeug, um die Verfügbarkeit von Diensten und Systemen sicherzustellen, doch ich stimme der Aussage „A documentation nightmare“ durchaus zu.
Überblick der Skripte für Keepalived
Genug konfiguriert, jetzt wird gescriptet! Alle Skripte befinden sich der Einfachheit halber ebenfalls im Verzeichnis /etc/keepalived/. Die Skripte sind dabei auf dem Master- und Backup-System identisch.
In aller Kürze zunächst ein kleiner Überblick:
| Skript | Funktion |
| shutdown.sh | Ausführung bei Beenden von Keepalived |
| check_pihole.sh | Prüfung Pi-Hole |
| notify.sh | Ausführung bei Ereignis einer VRRP-Instanz |
| config.sh | Konfiguration und Funktionsdefinition |
Bei allen handelt es sich um Bash-Skripte, wobei die ersten drei in der keepalived.conf angegeben sind und somit von Keepalived aufgerufen werden, während die Datei config.sh dafür zuständig ist, Konstanten und Funktionen zu definieren und zu Beginn von allen Skripten eingebunden wird.
Funktionen und Konfiguration: config.sh
Daher möchte ich auch mit dieser Datei beginnen, d.h. /etc/keepalived/config.sh:
#!/bin/bash
# config logger
LOG="logger -t keepalived-DRBD[$$] -p syslog" # do not use -i
LOGDEBUG="$LOG.debug"
LOGINFO="$LOG.info"
LOGWARN="$LOG.warn"
LOGERR="$LOG.err"
# keepalived config path
KEEPALIVED="/etc/keepalived"
#
# drbd config
#
DRBDADM="/sbin/drbdadm"
# DRBD resource
DRBDRESOURCE="r0"
# local mount point
MOUNTPOINT="/vol/drbd"
#
# function library
#
is_pihole_running () {
/usr/bin/docker ps -f name=pihole-pihole-1 | grep pihole >/dev/null 2>&1
PIHOLE_RUN_STATE=$?
if [ $PIHOLE_RUN_STATE -eq 0 ]; then
$LOGINFO "pihole instance found"
if [ "$(docker inspect -f "{{.State.Health.Status}}" pihole-pihole-1 )" == "healthy" ] ; then
$LOGINFO "pihole is RUNNING, no action necessary"
return 0
else if [ "$(docker inspect -f "{{.State.Health.Status}}" pihole-pihole-1 )" == "starting" ] ; then
$LOGINFO "pihole is STARTING, no action necessary"
return 0
fi
fi
fi
return 1
}
pihole_start () {
$LOGDEBUG "Starting pihole..."
cd /home/geschke/services/pihole && docker compose -f pihole.yml up -d
}
pihole_stop () {
$LOGDEBUG "Stopping pihole..."
cd /home/geschke/services/pihole && docker compose -f pihole.yml down
}
init_status() {
role=$( $DRBDADM role $DRBDRESOURCE )
cstate=$( $DRBDADM cstate $DRBDRESOURCE )
dstate=$( $DRBDADM dstate $DRBDRESOURCE )
$LOGDEBUG "in init_status role: $role cstate: $cstate dstate: $dstate"
}
set_backup() {
$LOGDEBUG "in set_backup"
# We must be sure to be in replication and secondary state
ensure_drbd_secondary
}
ensure_drbd_secondary() {
$LOGDEBUG "in ensure_drbd_secondary"
if ! is_drbd_secondary
then
set_drbd_secondary
return $?
fi
}
is_drbd_secondary() {
init_status
$LOGDEBUG "in is_drbd_secondary"
# If already Secondary, do nothing
if echo $role | grep -q ^Secondary
then
$LOGDEBUG "in is_drbd_secondary role Seconday found, cstate is $cstate"
if [ "$cstate" != 'StandAlone' ]
then
$LOGDEBUG "Already in BACKUP state..."
return 0
fi
fi
return 1
}
set_drbd_secondary() {
$LOGDEBUG "Try unmount first..."
if awk '{print $2}' /etc/mtab | grep -q "^$MOUNTPOINT"
then
$LOGWARN "Unmounting $MOUNTPOINT ..."
umount $MOUNTPOINT
$LOGWARN "Unmounted $MOUNTPOINT? {$?}"
fi
$LOGDEBUG "Set DRBD to secondary"
$DRBDADM secondary $DRBDRESOURCE
sleep 1
init_status
$LOGDEBUG "ROLE=$role CSTATE=$cstate DSTATE=$dstate"
}
set_master() {
x=20 # try to set primary 20 times, i.e. 20 seconds
$LOGDEBUG "before loop..."
while [ $x -ge 0 ]
do
init_status
if ! echo "$role" | grep -q ^Primary ; then
$LOGDEBUG "try to set primary now..."
$DRBDADM primary $DRBDRESOURCE
sleep 1
else
break
fi
sleep 1
$LOGDEBUG "x: $x"
let "x--"
done
init_status
if ! echo "$role" | grep -q ^Primary
then
$LOGDEBUG "Node is still not primary, return error"
return 1
fi
if ! awk '{print $2}' /etc/mtab | grep "^$MOUNTPOINT" >/dev/null
then
device=$( $DRBDADM sh-dev $DRBDRESOURCE )
$LOGDEBUG "Mounting $device on $MOUNTPOINT..."
#if ! mount $MOUNTPOINT
if ! mount -t xfs $device $MOUNTPOINT
then
$LOGERR "Unable to mount $MOUNTPOINT"
return 1
fi
fi
return 0
}
Zunächst werden Logging-Funktionen definiert, wobei letztlich syslog genutzt wird und für unterschiedliche Log-Levels (debug, info, warn, err) jeweils eine Funktion bereitstellt, die im Log leicht erkennbar sind angesichts des Bezeichners „keepalived-DRBD„. Danach werden Pfade und Parameter für DRBD definiert, zum einen die hier verwendete Ressource „r0„, zum anderen der bereits aus dem letzten Artikel bekannte Mountpoint /vol/drbd.
config.sh: Die Funktionen im Detail
Die Funktion „is_pihole_running“ prüft, ob der Pi-Hole-Docker-Container läuft und ob dessen Zustand „healthy“ oder „starting“ ist. Falls Pi-Hole nicht läuft oder einen anderen Zustand hat, wird ein Rückgabewert von 1, insofern die Kennzeichnung für einen Fehler, zurückgegeben. In der Funktion wird einfach das Kommando „docker ps -f name=pihole-pihole-1“ bzw. im weiteren Verlauf docker inspect aufgerufen, ebenfalls mit dem hier fest eingestellten Container-Namen „pihole-pihole-1“ . Eine Optimierung wäre z.B., diesen Namen im oberen Bereich als Variable zu definieren, um eine leichtere Anpassung an die eigene Umgebung zu ermöglichen.
Der Name des Docker-Containers ist jedoch nicht willkürlich, sondern erklärt sich aus der Verwendung von docker compose und dem entsprechenden Docker-Compose-File. Das Compose-File befindet sich auf den Servern in einem Verzeichnis „pihole„, der darin definierte Service hat ebenfalls den Namen „pihole„. Da Docker standardmäßig den Namen des Verzeichnisses als Projektnamen nutzt, und den Service-Namen sowie einen Index, durch „-“ getrennt, hinzufügt, lautet die Bezeichnung des Pi-Hole-Containers in diesem Fall „pihole-pihole-1„.
Die Funktion „pihole_start“ macht genau das, was ihr Name suggeriert. Nach Erzeugen eines entsprechenden Syslog-Eintrags wird in das Verzeichnis des Docker-Compose-Files gewechselt, wo der Aufruf des Start-Kommandos von Pi-Hole mittels docker compose erfolgt.
Das Pendant zum Stoppen von Pi-Hole lautet „pihole_stop„, die Funktion beendet Pi-Hole ebenfalls mittels Aufruf von docker compose.
Die Funktion „init_status“ liest einfach nur den aktuellen Status von DRBD, berücksichtigt dabei die Angaben „role„, „cstate“ und „dstate„, und schreibt diesen Status ins Log.
In „set_backup“ wird erst der eigene Aufruf geloggt, anschließend wird die Funktion „ensure_drbd_secondary“ aufgerufen. Diese Funktion soll sicherstellen, dass DRBD im Secondary-Zustand ist, indem sie zunächst prüft, ob der Node bereits im Secondary-Zustand ist, und falls nicht, wird die Funktion „set_drbd_secondary“ aufgerufen, um DRBD in den Secondary-Zustand zu bringen.
Die Funktion „is_drbd_secondary“ prüft anhand der Status-Angaben, ob sich DRBD im Secondary-Zustand befindet, die Auswertung erfolgt anhand des Rückgabewertes. Falls der Secondary-Zustand bereits vorliegt, wird 0 zurückgegeben, andernfalls 1.
In „set_drbd_secondary“ wird der DRBD-Node auf den Secondary-Zustand gesetzt. Falls die DRBD-Ressource noch gemountet ist, wird sie ausgehängt, anschließend der Node in den Secondary-Zustand gebracht.
Die gegenteilige Aufgabe führt „set_master“ aus. Zunächst erfolgten maximal 20 Versuche im Abstand von einer Sekunde, den Node in den Master-Zustand zu versetzen, d.h. nach ungefähr 20 Sekunden erfolgt der Abbruch und ein entsprechendes Logging einer Fehlermeldung sowie die Rückgabe des Fehler-Zustands. Im Erfolgsfall hingegen wird zunächst geprüft, ob die DRBD-Ressource bereits gemountet ist, falls nicht, wird ein mount ausgeführt. Auch hier werden Probleme geloggt und ggf. ein Fehler zurückgegeben, bei Erfolg hingegen ist der Rückgabewert 0.
Ereignisse und Steuerung: notify.sh
Das Skript „notify.sh“ wird von Keepalived aufgerufen, wenn ein bestimmtes Ereignis in der vrrp_instance eintritt. Damit hat es zentrale Bedeutung für die Steuerung von Aktionen wie etwa dem Starten und Stoppen von Diensten oder dem Handling von DRBD während eines Failovers. Zunächst der vollständige Code:
#!/bin/bash
# keepalived notify script
TYPE=$1
NAME=$2
STATE=$3
source $(dirname "$0")/config.sh
$LOGINFO "starting notify script with state {$STATE}"
#
# local vars
#
status=
role=
cstate=
dstate=
case $STATE in
"MASTER")
touch $KEEPALIVED/MASTER
# mark node as master and start Pi-Hole, if it is not running. Do nothing, if Pi-Hole is ok
$LOGINFO "MASTER state, now set master"
set_master
MASTER_STATE=$?
if [ $MASTER_STATE -eq 1 ]; then
$LOGERR "Could not set DRBD master, exit with error"
exit 1
fi
sleep 1
if is_pihole_running ; then
$LOGINFO "pihole is RUNNING or STARTING on master state, no action necessary"
else
$LOGINFO "pihole is NOT RUNNING on master state, starting pihole"
pihole_start
fi
exit 0 #$?
;;
"BACKUP")
rm $KEEPALIVED/MASTER
if is_pihole_running ; then
$LOGINFO "pihole is RUNNING on backup, stopping..."
pihole_stop
sleep 3
else
$LOGINFO "pihole is NOT RUNNING, do nothing"
fi
$LOGINFO "Set BACKUP state"
# wenn pihole läuft, beenden
# wenn pihole nicht läuft alles gut
set_backup
exit 0 #$?
;;
"STOP")
rm $KEEPALIVED/MASTER
$LOGINFO "entered STOP state, use shutdown script"
exit 0 #$?
;;
"FAULT")
rm $KEEPALIVED/MASTER
$LOGINFO "FAULT state"
if is_pihole_running ; then
$LOGINFO "pihole is RUNNING on fault state, stopping..."
pihole_stop
sleep 3
else
$LOGINFO "pihole is NOT RUNNING, do nothing"
fi
$LOGINFO "Set FAULT state, stop pihole, set drbd to secondary"
set_backup
exit 0 #$?
;;
*) $LOGINFO "unknown state {$STATE}, do nothing"
exit 1
;;
esac
Dem Skript werden von Keepalived einige Parameter übergeben und in den Variablen TYPE (Typ der VRRP-Instanz, NAME (Name der VRRP-Instanz) und STATE (neuer Zustand der Instanz, mögliche Werte: MASTER, BACKUP, STOP, FAULT) gespeichert. Anschließend wird das bereits vorgestellte Skript „config.sh“ eingelesen, so dass „notify.sh“ auf die darin definierten Funktionen und Variablen zurückgreifen kann.
notify.sh: Zustände und Aktionen
Die Funktionalität befindet sich im – zugegebenermaßen vielleicht etwas groß geratenen – Case-Block. Je nach übergebenem Status werden die entsprechenden Aktionen ausgeführt.
Wenn der Node durch Keepalived den Master-Status namens „MASTER“ erhält, wird zunächst eine Datei namens „MASTER“ in /etc/keepalived/ angelegt. Anschließend wird die Funktion „set_master“ aufgerufen, die versucht, DRBD auf dem Node in den Primary-Zustand zu versetzen. Falls dies nicht gelingt, wird das Skript mit einem Fehler beendet. Sofern der Node jedoch von DRBD als Primary gesetzt und die DRBD-Ressource gemountet wurde, wird geprüft, ob Pi-Hole bereits läuft, und falls nicht, durch den Aufruf von „pihole_start“ gestartet.
Im Zustand „BACKUP„ wird zunächst die ggf. vorhandene Datei „MASTER“ wieder entfernt, anschließend geprüft, ob Pi-Hole läuft. Falls Pi-Hole auf dem Node noch aktiv ist, wird es beendet, danach wird „set_backup“ aufgerufen, um DRBD in den Secondary-Zustand zu versetzen.
Der „STOP„-Zustand entfernt einfach nur die Datei „MASTER“ und protokolliert, dass der Node in den STOP-Zustand gewechselt ist. Weitere Aktionen werden nicht ausgeführt, da es sich um einen regulären Shutdown handelt, etwa bei einem manuellen Stoppen des Keepalived-Services. Dabei wird wiederum das Shutdown-Skript ausgeführt wird, das in der Direktive „shutdown_script“ angegeben ist.
Im „FAULT„-Zustand wird zunächst die Datei „MASTER“ entfernt, der Status, wie in allen anderen Fällen ebenso, geloggt, anschließend Pi-Hole ggf. gestoppt und DRBD in den Secondary-Zustand gesetzt.
Falls ein unbekannter Zustand eintritt, wird dies ebenfalls geloggt, außerdem das Skript mit einem Fehler beendet.
Damit erfüllt das notify.sh-Skript insgesamt die Aufgaben Verwaltung des DRBD-Zustands in Abhängigkeit des Status der VRRP-Instanz, Starten bzw. Stoppen von Pi-Hole je nach Zustand und Protokollierung aller Aktivitäten im Log.
Ausführung beim Stoppen: shutdown.sh
Als kleinen, unabhängigen Helfer würde ich das Skript shutdown.sh bezeichnen, das im globalen Bereich der keepalived.conf in der Direktive „shutdown_script“ Platz findet. Zunächst einmal der entsprechende Code aus der Datei „shutdown.sh“ :
#!/bin/bash
# shutdown script
source $(dirname "$0")/config.sh
$LOGINFO "starting shutdown script"
#
# local vars
#
status=
role=
cstate=
dstate=
$LOGDEBUG "in Shutdown STOP state"
if is_pihole_running ; then
$LOGDEBUG "pihole is RUNNING on STOP state, stopping..."
pihole_stop
$LOGDEBUG "ShutdownDRBD: after calling pihole_stop, now sleep for some seconds"
sleep 10
else
$LOGDEBUG "pihole is NOT RUNNING, do nothing"
fi
$LOGDEBUG "set STOP state, stop pihole, set drbd to secondary"
set_backup
exit 0
Der Kopfbereich ist nahezu identisch mit dem Notify-Skript. Die Hauptlogik wiederum prüft den Status von Pi-Hole und stoppt diesen Service, falls er noch läuft. Anschließend wird DRBD auf dem Node in den Secondary-Zustand versetzt, um sicherzustellen, dass der Node die Primary-Rolle nicht blockiert. Damit ist die Funktionalität dieselbe wie sie im BACKUP-Status im Notify-Skript vorhanden ist, der einzige Unterschied ist die Wartezeit von 10 Sekunden nach dem Beenden von Pi-Hole.
Prüfung von Pi-Hole mit check_pihole.sh
Zu guter Letzt das regelmäßig aufgerufene Skript „check_pihole.sh“:
#!/bin/bash
source $(dirname "$0")/config.sh
if [ -e $KEEPALIVED/MAINTENANCE ]; then
$LOGINFO "pihole maintenance file found, no action necessary"
exit 0
fi
if [ -e $KEEPALIVED/MASTER ]; then
$LOGINFO "keepalived MASTER file found"
if is_pihole_running ; then
exit 0
else
$LOGINFO "pihole is NOT RUNNING, return error"
exit 1 #should be 1, then it returns fault status
fi
else
$LOGINFO "no MASTER file found"
exit 0
fi
Das Einlesen der config.sh dürfte bereits bekannt sein, anschließend folgt eine Abfrage, ob eine Datei namens MAINTENANCE im Keepalived-Verzeichnis vorhanden ist. Falls ja, wird Erfolg vermeldet, d.h. kein Fehlerzustand zurückgegeben, auch wenn Pi-Hole möglicherweise nicht läuft. Ich hatte diese Anweisungen aus praktischen Gründen hinzugefügt. Denn normalerweise würde Keepalived im Fehlerfall, d.h. wenn Pi-Hole nicht läuft, dafür sorgen, dass der Backup-Host die Aufgabe übernimmt, inkl. des Umsetzens der IP-Adressen und der DRBD-Ressource. Dasselbe würde auch passieren, wenn man Pi-Hole manuell und somit absichtlich herunterfährt, um etwa ein Upgrade der Docker-Images durchzuführen.
Dass dies nicht erwünscht ist, liegt auf der Hand, und es lässt sich verhindern durch Anlegen einer Datei /etc/keepalived/MAINTENANCE. Diese muss nichts weiter beinhalten, sondern kann einfach mittels „sudo touch MAINTENANCE“ erzeugt werden. Danach verhält sich Keepalived ruhig, auch wenn sich Pi-Hole gerade im Upgrade-Prozess befindet. Sobald Pi-Hole wieder läuft, darf natürlich nicht vergessen werden, diese temporär angelegte Datei auch wieder zu entfernen.
Der Rest des Skripts fragt anhand der gesetzten MASTER-Datei ab, ob es sich bei dem System überhaupt um den primären Host handelt. Falls nicht, und das Skript somit auf dem Backup-System aufgerufen wird, muss Pi-Hole per Definition nicht laufen, folglich wird in keinem Fall ein Fehler zurückgegeben. Im anderen Fall, d.h. falls es sich um den Master handelt, und Pi-Hole laufen muss bzw. sollte, zeigt der Rückgabewert dementsprechend dessen Zustand, d.h. Erfolg oder Fehler.
Neue Systeme, Migration und deren Folgen
Die hier vorgestellte Konfiguration läuft seit inzwischen mehr als zwei Jahren ohne größere Probleme auf zwei VMs, die sich auf zwei unterschiedlichen Hosts befinden. Im Laufe der Zeit gab es einmal ein – selbst verschuldetes und tatsächlich ziemlich schräges – Problem. Im Zuge des Aufbaus der Systeme hatte ich komplett neu begonnen, d.h. zwei VMs eingerichtet, Ubuntu Server darauf gepackt, PowerDNS mit Docker, DRBD, Keepalived etc. vollständig neu installiert.
Währenddessen liefen die alten DNS-Server mit ihrem verteilten Dateisystem weiter, bis sie durch die neuen Systeme abgelöst wurden. Bereits in der alten Konfiguration sorgte Keepalived für die Übernahme der IP-Adresse, und Pi-Hole wurde ebenfalls zuvor genutzt. Auch die IPv4-Adresse von Pi-Hole, d.h. die Failover-Adresse war identisch zur neuen Konfiguration, schließlich sollte der Rest des Heimnetzes seine gewohnte DNS-IP-Adresse nutzen können.
Als ich einmal einen der Server, auf denen einige der VMs liefen, rebooten musste, war die Verwunderung groß, als Pi-Hole plötzlich auf einem völlig anderen System lief, sich dabei neu initialisiert und infolge dessen alle Einträge in Black- und Whitelists verloren hatte. Des Rätsels Lösung war simpel – ich hatte beim Abschalten der alten VMs eine davon tatsächlich nur abgeschaltet, nicht jedoch komplett gelöscht.
Aus guten Gründen und in voller Absicht, nur eben vergessen, sie im Nachgang auch vollständig zu löschen bzw. wenigstens den Neustart zu verhindern. Beim Hochfahren des Systems wurde somit auch die inzwischen alte DNS-VM mit Keepalived etc. gestartet, die sich prompt die Failover-IP-Adresse schnappte, Pi-Hole in einem – nun leeren – Verzeichnis startete und fortan meinte, erneut der Heimnetz-DNS-Server sein zu können. Nach dem Herunterfahren und Löschen jener VM war jedoch schnell der gewünschte Zustand wiederhergestellt.
Alles super, nur fehlt noch IPv6!
Zum Schluss dieses erneut längeren Beitrags möchte ich noch auf IPv6 hinweisen, denn dies war in der Erstinstallation noch nicht vorgesehen. Und damit auch auf die Ankündigung im Beitrag über statische IPv6-Adressen im Heimnetz eingehen. Die Nutzung von IPv6 in diesem Kontext umfasst zwei Aspekte.
Erstens müssen die PowerDNS-Server IPv6-Adressen verwalten können, so dass bei einer AAAA-Abfrage nach einem lokalen Host auch dessen IPv6-Adresse zurück geliefert wird.
Zweitens müssen die beteiligten Server, d.h. insbesondere Pi-Hole, unter einer statischen, internen und damit IPv6-ULA-Adresse erreichbar sein.
PowerDNS und IPv6
Der erste Punkt ist nicht nur schnell, sondern auch sehr einfach zu realisieren. Denn der entsprechende AAAA-Eintrag muss nur bei PowerDNS eingetragen werden, PowerDNS und auch PowerDNS-Admin beherrschen den Umgang mit derartigen Einträgen seit geraumer Zeit. In PowerDNS-Admin zeigt sich ein AAAA-Eintrag somit wie jeder andere auch:
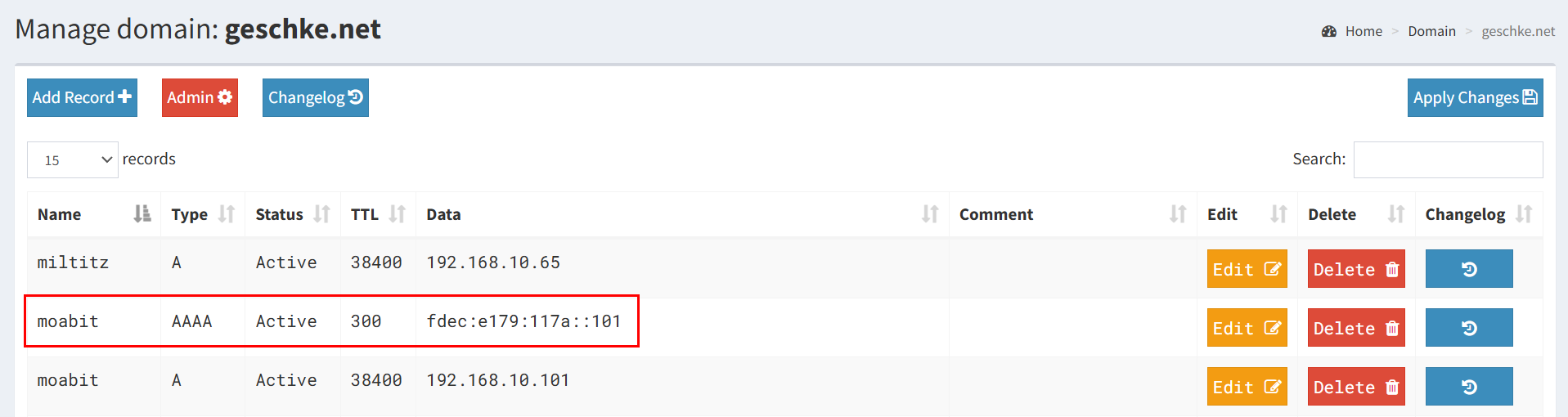
Nach Speichern und Synchronisieren kann der AAAA-Eintrag entweder direkt von einem der DNS-Server oder mittels Pi-Hole abgefragt werden. Bei der Abfrage kommt es ausschließlich darauf an, den AAAA-Eintrag für IPv6 anstatt des standardmäßig verwendeten A-Eintrags für IPv4 abzurufen. Ob die Anfrage an die DNS-Server bzw. Pi-Hole unter deren IPv4- oder IPv6-Adresse erfolgt, ist hingegen irrelevant.
geschke@marzahn:/etc/keepalived$ dig @192.168.10.19 aaaa moabit.geschke.net ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @192.168.10.19 aaaa moabit.geschke.net ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58320 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;moabit.geschke.net. IN AAAA ;; ANSWER SECTION: moabit.geschke.net. 103 IN AAAA fdec:e179:117a::101 ;; Query time: 10 msec ;; SERVER: 192.168.10.19#53(192.168.10.19) (UDP) ;; WHEN: Mon Jan 20 19:20:42 UTC 2025 ;; MSG SIZE rcvd: 75
Statische IPv6-ULA-Adressen auf den Hosts
Darüber hinaus sollen jedoch sowohl die DNS-Server, d.h. sowohl die Hosts, als auch die PowerDNS-Docker-Container bzw. deren virtuelle IP-Adressen, als auch Pi-Hole mittels IPv6-Adressen erreichbar sein. Zur Verwendung kommen dabei die bereits bekannten IPv6-Adressen aus dem ULA-Bereich, wobei ich der Einfachheit halber das letzte Byte der IPv4-Adressen für deren Pendant als IPv6 verwendet habe. Der Host „moabit“ aus dem obigen Beispiel mit der IPv4-Adresse „192.168.10.101“ erhält somit als Interface-ID die „::101„, was insgesamt zur IPv6-ULA-Adresse „fdec:e179:117a::101/64“ führt. Dem aufmerksamen Leser mag nicht entgangen sein, dass die „101“ eigentlich eine „0x101“ ist, da IPv6-Adressen das hexadezimale Zahlensystem verwenden, es wäre dezimal demnach die 257, aber da mein Kopf keinen Zahlensystem-Konverter beinhaltet, ignoriere ich diesen Umstand wohlweislich.
Die Einstellungen des Netzwerks finden unter Ubuntu in der Netzwerk-Konfigurations-Abstraktionsschicht netplan in einer yaml-Datei im Verzeichnis /etc/netplan Platz. Die IPv4-Adressen waren darin bereits statisch vergeben, im Folgenden der vollständige Inhalt des primären Hosts:
network:
version: 2
renderer: networkd
ethernets:
ens3:
dhcp6: yes
addresses:
- 192.168.10.116/24
- 192.168.10.220/24
- fdec:e179:117a::116/64
- fdec:e179:117a::220/64
routes:
- to: default
via: 192.168.10.4
nameservers:
search: [geschke.net]
addresses: [192.168.10.220,192.168.10.221]
Für IPv6 wurden die entsprechenden statischen ULA-Adressen einfach nach dem bereits beschriebenen Schema hinzugefügt. Die Failover-IP-Adresse ist hierbei nicht enthalten, da die Zuweisung durch Keepalived erfolgt. Die Einstellung „dhcp6: yes“ bezieht sich auf die globalen, vom Provider bzw. vom vorgelagerten Router vergebenen IPv6-Adressen, die friedlich neben den internen ULA-Adressen koexistieren. Die Konfiguration des Backup-Hosts verläuft analog mit den jeweiligen anderen anderen Adressen.
IPv6 für PowerDNS im Docker-Container
Damit die DNS-Server, die mittels Docker-Containern realisiert sind, auch unter der entsprechenden IPv6-Adresse ansprechbar sind, muss deren Konfiguration im Docker-Compose-File ebenfalls angepasst werden. Denn bis dato war der notwendige Port 53 nur unter der jeweiligen IPv4-Adresse verfügbar. Da letztlich der „dnsdist„-Dienst dafür zuständig ist, DNS-Anfragen entgegenzunehmen, muss folglich nur der entsprechende Abschnitt im Docker-Compose-File erweitert werden:
dnsdist:
image: geschke/dnsdist
restart: always
ports:
- "192.168.10.220:53:53/udp"
- "192.168.10.220:53:53/tcp"
- "[fdec:e179:117a::220]:53:53/udp"
- "[fdec:e179:117a::220]:53:53/tcp"
volumes:
- type: bind
source: ./dnsdist/dnsdist.conf
target: /etc/dnsdist/dnsdist.conf
networks:
dns_net:
ipv4_address: 172.30.1.50
Hier wurden der Port 53 auf der IPv6-Adresse für tcp und udp geöffnet. An dem übrigen Aufbau des Docker-Compose-Files ändert sich nichts. Um es noch einmal zu verdeutlichen: Die Docker-interne Vernetzung der für den DNS-Betrieb zuständigen Container, d.h. PowerDNS, PowerDNS-Admin, PowerDNS-Recursor und dnsdist hat sich nicht geändert. Dabei wird weiterhin IPv4 eingesetzt, da es aus meiner Sicht letztlich irrelevant ist, ob diese per IPv6 oder IPv4 kommunizieren. Schließlich kommt es einzig darauf an, dass die internen DNS-Server im Heimnetz per IPv6 ansprechbar sind, und genau das wird durch die Ergänzung der IPv6-Adressen für den dnsdist-Service ermöglicht.
Somit können nun DNS-Anfragen nicht nur an die IPv4-, sondern auch an die IPv6-Adresse des Nameservers erfolgen:
geschke@gatow:~$ dig @fdec:e179:117a::220 a moabit.geschke.net ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @fdec:e179:117a::220 a moabit.geschke.net ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 65303 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;moabit.geschke.net. IN A ;; ANSWER SECTION: moabit.geschke.net. 38400 IN A 192.168.10.101 ;; Query time: 14 msec ;; SERVER: fdec:e179:117a::220#53(fdec:e179:117a::220) (UDP) ;; WHEN: Tue Jan 21 11:13:40 UTC 2025 ;; MSG SIZE rcvd: 63
IPv6 für Pi-Hole im Docker-Container
Als letzter Dienst verbleibt Pi-Hole, der ebenfalls unter der von Keepalived vergebenen IPv6-Adresse erreichbar sein soll. Die Konfiguration von Keepalived wurde weiter oben bereits erläutert, insofern stehen die IPv4- und IPv6-Adressen „192.168.10.19“ und „fdec:e179:117a::19/64“ auf dem primären Host zur Verfügung.
Auch in den Docker-Compose-Files – auf beiden Hosts – wurde nur der entsprechende „ports„-Abschnitt durch die IPv6-Adressen ergänzt:
ports: - "127.0.0.1:53:53/udp" - "127.0.0.1:53:53/tcp" - "192.168.10.19:53:53/tcp" - "192.168.10.19:53:53/udp" - "192.168.10.19:67:67/udp" - "192.168.10.19:80:80" - "192.168.10.19:443:443" - "[fdec:e179:117a::19]:53:53/udp" - "[fdec:e179:117a::19]:53:53/tcp" - "[fdec:e179:117a::19]:67:67" - "[fdec:e179:117a::19]:80:80" - "[fdec:e179:117a::19]:443:443"
Da auch das Web-Interface von Pi-Hole über die IPv6-Adresse zugänglich sein soll, sind die Ports 80 und 443 ebenfalls enthalten, der Port 67 zeigt sich für DHCP zuständig, was in Pi-Hole enthalten ist, aktuell jedoch nicht genutzt wird.
Nach dem Restart des Containers zeigt auch Pi-Hole bei der Anfrage an dessen IPv6-Adresse das gewünschte Ergebnis:
geschke@gatow:~$ dig @fdec:e179:117a::19 aaaa moabit.geschke.net ; <<>> DiG 9.18.28-0ubuntu0.24.04.1-Ubuntu <<>> @fdec:e179:117a::19 aaaa moabit.geschke.net ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16737 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 1232 ;; QUESTION SECTION: ;moabit.geschke.net. IN AAAA ;; ANSWER SECTION: moabit.geschke.net. 64 IN AAAA fdec:e179:117a::101 ;; Query time: 4 msec ;; SERVER: fdec:e179:117a::19#53(fdec:e179:117a::19) (UDP) ;; WHEN: Tue Jan 21 11:24:21 UTC 2025 ;; MSG SIZE rcvd: 75
Fazit mit ein wenig IPv6: Freundschaft!?
Damit wäre die Konfiguration insgesamt abgeschlossen. Oder auch – endlich! Wobei sich die Änderungen für die IPv6-ULA-Adressen durchaus in Grenzen halten, einzig die Schreibweise verursacht bei mir immer wieder Kopfschütteln. Bei der DNS-Abfrage mittels dig oder auch beim Ping ohne eckige Klammern, ebenso bei netplan, im Browser und in den Docker-Compose-Files sind eckige Klammern wiederum notwendig usw., was zwar angesichts möglicher doppelter Doppelpunkte erklärbar, aber andererseits doch irgendwie unschön wirkt. So richtig tiefe Freundschaft verbinde ich insofern mit IPv6 noch nicht, aber immerhin ist in meinem Heimnetz nun ein Pi-Hole-, d.h. DNS-Server unter einer internen IPv6-Adresse erreichbar, der bei pfSense eingetragen und damit an die Clients weitergegeben werden kann.

 im Heimnetz mit pfSense")

