FerretDB? Nie gehört? Tatsächlich erging es mir bis vor einigen Monaten nicht anders, bis mir der Name im Golang-Weekly-Newsletter von Anfang September 2024 begegnete. Die Kurzbeschreibung weckte meine Aufmerksamkeit – übersetzt ungefähr eine Datenbank, die sich wie MongoDB verhält, mit PostgreSQL im Hintergrund.
Das klang schon mal interessant, aber da ich im aktuellen, kleinen Programmierprojekt bereits MariaDB verwendete und die Entwicklung von Datenbanken auch nur sehr nebenbei verfolgte, landete die URL von FerretDB erstmal auf meinem „später ansehen“-Stack – also dem FIFO-Speicher, den man üblicherweise nach n Jahren nochmal durchforstet, nur um dann zu bemerken, was in der Zwischenzeit schon wieder obsolet geworden war.
FerretDB? DocumentDB?
Bei FerretDB sah die Sache aber letztlich anders aus. Ende Januar 2025 wurde mir ein Blog-Eintrag von Microsoft in eine der vielen Timelines gespült, in dem eine Open-Source-Entwicklung namens DocumentDB vorgestellt wurde. Das hörte sich zunächst nach einer Dokumentendatenbank von Microsoft an, tatsächlich handelt es sich aber um eine Erweiterung für PostgreSQL. Und auch FerretDB wurde in dem Blog-Artikel genannt, als eine direkt nutzbare Document Database. Da ich mich vor vielen Jahren etwas intensiver mit dem Thema „NoSQL“-Datenbanken beschäftigt hatte, war die alte Neugier sozusagen wieder geweckt. Parallel dazu war ich im Programmierprojekt an einem Punkt angekommen, an dem einige SQL-Abfragen – sagen wir mal – etwas suboptimal geworden waren, und der Gedanke somit nahe lag, sich vielleicht doch mit einer anderen Art der Speicherung auseinander zu setzen. In diesem Artikel möchte ich FerretDB und deren Hintergründe kurz vorstellen, mit einem kleinen Abstecher in die Installation und praktische Anwendung. Und zum Schluss folgt noch ein kleiner Benchmark.
MongoDB-Lizenz-Geschichte(n)
MongoDB ist zweifellos die populärste und bekannteste Dokumentendatenbank, zumindest wenn man dem Ranking auf DB-Engines Glauben schenken mag. Auch ich hatte als Entwickler bereits Erfahrungen mit MongoDB machen dürfen, allerdings liegen diese ungefähr zehn Jahre zurück. Zu der Zeit war MongoDB noch als Open-Source unter der GNU Affero General Public License (AGPL) veröffentlicht, was wesentlich zur breiten Nutzung und Popularität beigetragen haben dürfte. Das änderte sich jedoch 2018, als die Lizenzierung geändert wurde. Fortan wurde MongoDB unter der proprietären Server Side Public License (SSPL) veröffentlicht, die einige Restriktionen beinhaltet. Mit der SSPL müssen Anbieter von MongoDB-Services auch den Quellcode des entsprechenden Services unter derselben Lizenz veröffentlichen. Dasselbe gilt für Tools und Anwendungen, die sich um diesen Service ranken, wie etwa Management-Tools, Backup- oder Monitoring-Systeme. Natürlich ist es verständlich, dass MongoDB letztlich Geld mit ihren Produkten verdienen möchte, aber dass die Änderung der Lizenz nicht nur bei Cloud-Anbietern, sondern auch in der Community für einigen Unmut gesorgt hat, dürfte leicht nachvollziehbar sein. Rein formell ist die SSPL auch keine Open-Source-Lizenz mehr, sie wurde von der Open Source Initiative (OSI) abgelehnt, was dazu führte, dass MongoDB aus einigen Linux-Distributionen entfernt wurde.
Nichtsdestotrotz hatten die Features von MongoDB dafür gesorgt, dass seit der Erstveröffentlichung im Jahre 2009 viele Anwendungen entwickelt wurden, und ebenso etliches an Infrastruktur, z.B. Treiber, Frameworks, UI-Tools, rund um MongoDB aufgebaut worden waren. Für die Entwickler-Community fühlte sich jedoch die Lizenzänderung von MongoDB wie ein Verrat an den Open-Source-Prinzipien an.
Es waren einmal… die Anfänge von FerretDB
So entstand im Jahr 2021 eine Initiative, die das Ziel hatte, eine vollständig kompatible, quelloffene Alternative zu MongoDB zu entwickeln. Zunächst noch unter dem Namen MangoDB, bereits einen Monat später umbenannt in FerretDB, was eine klarere Identität schaffen und die Ernsthaftigkeit des Vorhabens unterstreichen sollte. Dabei sollte FerretDB als Drop-In-Ersatz für MongoDB dienen, so dass alle Tools und Treiber weiterhin Verwendung finden konnten. FerretDB unterstützt dabei das MongoDB-Wire-Protocol zur Kommunikation der Clients mit dem Datenbank-Server. Die frühen Versionen von FerretDB bis hin zum Ende des Jahres 2024 konzentrierten sich zunächst darauf, die wichtigsten Funktionen von MongoDB zu implementieren, etwa grundlegende Abfragen und Aggregationen bei Kompatibilität mit MongoDB-Treibern. Gleichzeitig wurde die Entwickler-Community in einem offenen Entwicklungsprozess auf GitHub mit eingebunden, so dass Entwickler und Nutzer schnell und direkt neue Funktionen beisteuern, Tests in eigenen Produktionsumgebungen durchführen und somit Feedback geben konnten.
Hinter FerretDB stehen einige bekannte Persönlichkeiten aus dem Umfeld von Percona, einem Unternehmen, das im Bereich Open-Source-Datenbanksoftware Support und Service anbietet und in eben jener Community recht bekannt sein dürfte. Der Gründer von Percona, Peter Zaitsev, fungiert dabei als Berater, der CEO von FerretDB, Peter Farkas, kann auf Erfahrungen in den Bereichen Datenbanken und Big Data mit Stationen bei Percona und Cloudera zurückblicken, während mit Alexey Palazhchenko ein CTO vorhanden ist, der umfangreiche Erfahrungen mit der Programmiersprache Go hat und bei Percona die Entwicklung und Architektur der Monitoring- und Management-Lösung leitete.
Neben der Open-Source-Lösung bietet das Unternehmen hinter FerretDB auch kommerziellen Support und Managed Services an, eine Cloud-Lösung von FerretDB ist ebenfalls angekündigt.
Es wird einmal? Vision und Zukunft von FerretDB
Tatsächlich geht die Vision der Gründer jedoch noch einen Schritt weiter, als nur eine MongoDB-kompatible Datenbank-Lösung anzubieten. Peter Farkas beschreibt auf seiner Site „OpenDocDB Workgroup“ die Idee von offenen Standards für Dokumentendatenbanken. Ein Ziel wäre beispielsweise die Schaffung einer Standard-Abfrage-Sprache für JSON-Dokumentendatenbanken, um Interoperabilität zwischen unterschiedlichen Systemen zu erreichen. Dies würde die Möglichkeit zur Migration zwischen den Produkten erleichtern, die aktuell schwierig bis unmöglich erscheint. Für Kunden hätte dies den Vorteil, die starke Anbieterbindung zu verringern, auf Seiten der Unternehmen würde es Innovationen und gesunden Wettbewerb fördern. Ich bin durchaus gespannt auf die weitere Entwicklung dieser Idee, immerhin haben sich schon einige Unterstützer gefunden, und in der Rolle als Entwickler wäre mir ein derartiger Standard natürlich sehr willkommen, auch wenn gerade das Beispiel SQL zeigt, dass es letztlich nur ein Quasi-Standard ist. Die Grundlagen sind zwar identisch, aber im Detail existieren noch ausreichend viele Unterschiede, die gerade jene wünschenswerte Interoperabilität verhindern und eine Anpassung des SQL-Codes auf die jeweils verwendete Datenbank unumgänglich werden lassen.
Was ist FerretDB denn nun wirklich?
Doch zurück zu FerretDB selbst und der Technologie dahinter. FerretDB ist ein in Go (Golang) geschriebener Proxy, der das MongoDB-Wire-Protokoll empfängt und diese Anfragen in SQL umwandelt, die von PostgreSQL verarbeitet werden. Zur Verdeutlichung folgende Skizze, die von der FerretDB-Dokumentation übernommen wurde:

Funktionsweise FerretDB (in Anlehnung an https://docs.ferretdb.io/)
Seit Version 2.0 stützt sich FerretDB dabei auf die von Microsoft entwickelte PostgreSQL-Erweiterung DocumentDB, dazu gleich mehr. Die ersten Versionen von FerretDB bis hin zur erst Ende 2024 erschienenen Version 1.24 verfolgten indessen noch eine andere Strategie. Einerseits hatten die Entwickler versucht, mehrere Datenbank-Backends zu unterstützen, andererseits gab es wesentliche Unterschiede in der Speicherung der Daten selbst. Neben PostgreSQL konnte SQLite als Backend verwendet werden, der Support für SAP HANA befand sich im Alpha-Stadium. Letztlich entsprachen MongoDB-Collections PostgreSQL-Tabellen, einzelne Dokumente wurden in den jeweiligen Zeilen in einer Spalte mit dem JSONB-Datentyp abgelegt. Analog dazu war die Nutzung des JSON-Datentyps von SQLite, in der FerretDB-Dokumentation noch „JSON1“ genannt. Die Verwendung der JSON-Datentypen erforderte jedoch einigen Aufwand bei der Übersetzung von MongoDB-Requests, schließlich musste der MongoDB-„Dialekt“ in SQL und die Datenbank-eigenen Funktionen zum Handling von JSON-Strukturen transformiert werden. Dieser Aufwand verringerte sich wesentlich durch die Nutzung der DocumentDB-Extension von Microsoft, die Ende Januar 2025 veröffentlicht wurde.
Im Hintergrund: PostgreSQL mit DocumentDB
Microsoft kündigt dabei in einem Blog-Artikel die Verfügbarkeit von DocumentDB als eine Plattform für Dokumentendatenbanken. Dabei handelt es sich um die Technologie hinter des Cloud-Dienstes Azure Cosmos DB für MongoDB, basierend auf PostgreSQL. Die Ziele dahinter – einen Standard für Open-Source-Dokumentendatenbanken zu schaffen, oder die Interoperabilität zwischen NoSQL-Datenbanken zu erreichen, zeigen eindeutig Parallelen zum Ansatz der OpenDocDB-Initiative. Für Microsoft fast ein wenig erstaunlich ist die sehr freie Lizenzierung unter der MIT-Lizenz, was bedeutet, dass Entwickler sowie Nutzer keine Einschränkungen haben, das Projekt in neue oder bestehende Lösungen zu integrieren. Ebenfalls betont Microsoft die Möglichkeit der Mitarbeit und Weiterentwicklung, die Initiatoren stellen dazu die üblichen Ressourcen wie das GitHub-Repository und einen Discord-Kanal zur Verfügung. Auch sei das Feedback von Nutzern sehr erwünscht.
Rein technisch ist DocumentDB eine PostgreSQL-Extension, die aus zwei Komponenten besteht. Dabei optimiert die erste Komponente, pg_documentdb_core, die Unterstützung für den BSON-Datentyp (Binary JavaScript Object Notation) in PostgreSQL. Die Fähigkeit, BSON-Dokumente zu parsen und zu manipulieren, Felder zu indizieren, inklusive Einzelspaltenindizes, Indizes aus mehreren Schlüsseln oder zusammengesetzte Indizes bis hin zur Optimierung von Abfragekriterien, werden dabei vollständig von dieser Schicht übernommen. Des Weiteren befinden sich ein Authentifizierungsmechanismus, einschließlich SCRAM (Salted Challenge Response Authentication), sowie die Möglichkeit der Nutzung von Vektor-Suchabfragen, basierend auf der pg_vector-Extension, ebenfalls in dieser Komponente. Bei der zweiten Komponente handelt es sich um pg_document_api, die eine API-Schicht anbietet, die sich um die Implementierung von CRUD-Operationen (Create, Read, Update, Delete), Abfrage-Funktionalität und Verwaltung von Indizes kümmert.
SQL meets Document Database
Was zunächst ein wenig abstrakt daher kommt, wird durch die Beispiele, hier nur kurz dargestellt und von der Microsoft-Seite übernommen, vielleicht ein wenig deutlicher. Auf die Beschreibung der Installation verzichte ich hierbei, interessanter erscheinen mir die Beispiele für die üblichen CRUD-Operationen. Beispielsweise wird eine Collection in einer Datenbank namens „documentdb“ angelegt mittels:
SELECT documentdb_api.create_collection('documentdb','patient');
Um ein Dokument einzufügen, wäre folgendes SQL-Statement nötig:
select documentdb_api.insert_one('documentdb','patient',
'{ "patient_id": "P001", "name": "Alice Smith",
"age": 30, "phone_number": "555-0123",
"registration_year": "2022",
"conditions": ["Diabetes", "Hypertension"]
}');
Die Formatierung soll der leichteren Lesbarkeit dienen, ist hingegen irrelevant, tatsächlich handelt es sich um eine einzige Zeile. Dass das Hinzufügen eines Dokuments mittels einer SELECT-Anweisung erfolgt, sieht auch auf den zweiten Blick sehr gewöhnungsbedürftig aus, ist jedoch andererseits verständlich, da dabei in letzter Instanz die PostgreSQL-Extension pg_document_api angesprochen wird, die wiederum die Anfrage übersetzt. Und spätestens an dieser Stelle dürfte auch eine Ähnlichkeit zur Entwickler-API von MongoDB auffallen, so würde das Pendant in der MongoDB-Shell wie folgt lauten:
db.patient.insertOne({
"patient_id": "P001", "name": "Alice Smith", "age": 30, "phone_number": "555-0123",
"registration_year": "2022",
"conditions": ["Diabetes", "Hypertension"]
});
Weitere Beispiele finden sich insbesondere auf der GitHub-Seite zum Projekt. Als Entwickler, insofern Nutzer von FerretDB als Ersatz von MongoDB, muss man sich jedoch gar nicht weiter mit dieser Schicht bzw. den merkwürdig anmutenden SQL-Statements beschäftigen, denn genau diese Aufgabe übernimmt FerretDB. So wird FerretDB 2.0 dabei von Microsoft im Blog-Eintrag auch als eine bestehende und direkt einsatzbereite Lösung beschrieben, die DocumentDB als Backend-Technologie beinhaltet.
Erste Schritte mit FerretDB – Installation und Betrieb
Wohl nicht ganz zufällig ist FerretDB 2.0 RC1, also der erste Release Candidate, am selben Tag der Ankündigung von Microsofts DocumentDB erschienen. Tatsächlich habe ich die ersten Tests mit dieser Version gestartet, d.h. die Migration der Anwendung begonnen. Der Einfachheit halber wurde FerretDB mit Hilfe von Docker, wie auf der entsprechenden Dokumentations-Seite beschrieben, installiert. Dazu reicht folgendes Docker-Compose-File:
services:
postgres:
image: ghcr.io/ferretdb/postgres-documentdb:17-0.102.0-ferretdb-2.0.0
platform: linux/amd64
restart: always
#ports:
# - 5432:5432
environment:
- POSTGRES_USER=<username>
- POSTGRES_PASSWORD=<password>
- POSTGRES_DB=postgres
volumes:
- ./data:/var/lib/postgresql/data
ferretdb:
image: ghcr.io/ferretdb/ferretdb:2.0.0
restart: always
ports:
- 27017:27017
environment:
- FERRETDB_POSTGRESQL_URL=postgres://<username>:<password>@postgres:5432/postgres
networks:
default:
name: ferretdb
Dieses Compose-File beinhaltet bereits die aktuelle, Version 2.0 GA (General Availability) von FerretDB. Die Freigabe des PostgreSQL-Ports ist hier einkommentiert, da nicht notwendig für den Betrieb. Zu Beginn und letztlich aus Neugier hatte ich den Port zunächst freigegeben, um mittels PostgreSQL-Clients darauf zugreifen zu können. Wie üblich sorgt Docker Compose für den Start, z.B.: docker compose -f ferretdb.yml up -d .
Um das System sauber zu halten und keinen MongoDB-Client installieren zu müssen, kann wiederum Docker verwendet werden. Im „mongo„-Docker-Image befindet sich auch die MongoDB-Shell, der Einfachheit halber habe ich das Kommando zum Aufruf als Shell-Skript verpackt:
#!/bin/bash docker run --rm -it --network=ferretdb --entrypoint=mongosh mongo "mongodb://<username>:<password>@ferretdb/"
Falls FerretDB erfolgreich gestartet wurde, sorgt der Start des Skript-Einzeilers für die Verbindung:
geschke@gatow:~/services/ferretdb2$ ./mongosh.sh Current Mongosh Log ID: 67d864f806709c03f66b140a Connecting to: mongodb://<credentials>@ferretdb/?directConnection=true&appName=mongosh+2.4.2 Using MongoDB: 7.0.77 Using Mongosh: 2.4.2 For mongosh info see: https://www.mongodb.com/docs/mongodb-shell/ To help improve our products, anonymous usage data is collected and sent to MongoDB periodically (https://www.mongodb.com/legal/privacy-policy). You can opt-out by running the disableTelemetry() command. ------ The server generated these startup warnings when booting 2025-03-17T18:07:53.279Z: Powered by FerretDB v2.0.0 and DocumentDB 0.102.0 (PostgreSQL 17.4). 2025-03-17T18:07:53.279Z: Please star 🌟 us on GitHub: https://github.com/FerretDB/FerretDB and https://github.com/microsoft/documentdb. 2025-03-17T18:07:53.279Z: The telemetry state is undecided. Read more about FerretDB telemetry and how to opt out at https://beacon.ferretdb.com. ------ test>
Dies ist natürlich nur ein erster Test, in der MongoDB-Shell können alle Kommandos ausgeführt werden, etwa das Anlegen von Datenbanken, Collections, Dokumenten, das Abfragen usw.. Ein wenig übersichtlicher wird dies durch die Nutzung von MongoDB-UI-Clients, so funktioniert die freie – im Sinne von kostenlos nutzbare – MongoDB-eigene UI namens Compass problemlos mit FerretDB. Mit Version 2.0 RC1 gab es dabei noch Einschränkungen in der Betrachtung von Indizes, bei 2.0 sind diese inzwischen behoben.
Da FerretDB als Ersatz für MongoDB dient und dessen Protokolle nachbildet, können alle Treiber nahtlos verwendet werden. Auf umfangreiche Beispiele verzichte ich daher, im Folgenden nur ein minimales Code-Fragment, das die MongoDB-Go-Treiber nutzt. Nach der Installation der MongoDB-Treiber mittels „go get go.mongodb.org/mongo-driver/mongo“ und „go get go.mongodb.org/mongo-driver/bson“ fügt der folgende Code zunächst ein Dokument ein und ruft es anschließend wieder ab:
package main
import (
"context"
"fmt"
"log"
"go.mongodb.org/mongo-driver/bson"
"go.mongodb.org/mongo-driver/mongo"
"go.mongodb.org/mongo-driver/mongo/options"
)
func main() {
// Verbindung zu FerretDB herstellen
client, err := mongo.Connect(context.TODO(), options.Client().ApplyURI("mongodb://<username>:<password>@gatow.geschke.net:27017"))
if err != nil {
log.Fatal("Failed to connect:", err)
}
defer client.Disconnect(context.TODO())
// Datenbank und Collection auswählen
collection := client.Database("testdb").Collection("patients")
// Ein Dokument einfügen
patient := bson.M{"patient_id": "P001", "name": "Alice Smith", "age": 30, "conditions": []string{"Diabetes", "Hypertension"}}
_, err = collection.InsertOne(context.TODO(), patient)
if err != nil {
log.Fatal("Insert failed:", err)
}
fmt.Println("Inserted document:", patient)
// Dokumente abrufen
cursor, err := collection.Find(context.TODO(), bson.M{})
if err != nil {
log.Fatal("Find failed:", err)
}
defer cursor.Close(context.TODO())
fmt.Println("Retrieved documents:")
for cursor.Next(context.TODO()) {
var result bson.M
if err := cursor.Decode(&result); err != nil {
log.Println("Decode error:", err)
continue
}
fmt.Println(result)
}
if err := cursor.Err(); err != nil {
log.Fatal("Cursor error:", err)
}
}
In meiner Anwendung zeigten sich beim Betrieb von FerretDB keinerlei Probleme, neben den üblichen CRUD-Abfragen ließen sich auch MongoDB Aggregation Pipelines nutzen, d.h. Daten in mehreren Verarbeitungsschritten transformieren und analysieren. Auch das Filtern, Sortieren oder Setzen von Limits und Offsets funktionierte wie erwartet, ebenso die Verwendung von Dokumenten mit mehreren Ebenen, in Go realisiert als verschachtelte Structs.
Die einzige Hürde, die mir beim Update von Version 2.0 RC1 auf 2.0 GA begegnete, lag in der Verwendung der PostgreSQL-Versionen begründet. Die erste RC-Version von FerretDB stützte sich noch auf PostgreSQL Version 16, wovon FerretDB ein mit DocumentDB erweitertes Docker-Image bereit gestellt hatte. Diese Variante hatte ich bis zum Erscheinen der 2.0 GA Version verwendet, und während der Entwicklung auch bereits für die Speicherung von Test-Daten genutzt. Mit Version 2.0, bzw. evtl. bereits während der weiteren Zwischen-Versionen, die ich aber nicht eingesetzt hatte, wurde nun auf die Version 17 von PostgreSQL zurückgegriffen. Nach Änderung der Angaben im Docker-Compose-File schlug der Start von FerretDB zunächst fehl, da sich die internen Datenformate der PostgreSQL-Versionen unterschieden, und keine automatische Migration durchgeführt wurde. Dies hätte sich sicherlich mittels pg_upgrade beheben lassen, der Einfachheit halber habe ich einen Ex- und Import der Test-Daten und einen „sauberen“ Neustart vorgezogen.
Dumme Idee: Benchmarks
Nach einigen Wochen von sehr positiven Erfahrungen mit FerretDB bin ich irgendwie auf die Idee gekommen, doch einmal einen kleinen Benchmark von MongoDB gegen FerretDB laufen zu lassen. Dazu sollte MongoDB ebenfalls mittels Docker auf demselben Host bzw. derselben kleinen Entwicklungs-VM gestartet werden.
Einschub: Ein paar MongoDB-Docker-Querelen
Die Nutzung von MongoDB als Docker-Container war jedoch mit einigen Hürden gespickt. Zunächst nennt die MongoDB-Dokumentation zu Docker einige unterschiedliche MongoDB-Images, beschreibt im Verlauf dabei die Nutzung eines sogenannten offiziellen MongoDB-Community-Images. Dieser – super offizielle – Image des MongoDB Community genannten Server-Systems ist mit Myriaden Tags verfügbar, leider beginnt der Liste der „neuesten“ Versionen nicht beim aktuellen Versionsstrang 8.0.x, sondern bei einer Version 6.x. Der Link auf den „Getting Starting Guide“ funktioniert immerhin, führt aber zu einer völlig veralteten Anleitung, die sich ebenfalls noch mit Version 6.x beschäftigt. Somit wollte ich die aktuelle Version 8.0.5 mittels Docker Compose nutzen, was schlicht und einfach scheiterte. Beim Start wurden Fehler von irgendwelchen Python-Sequenzen angezeigt, so dass MongoDB sich nicht per Docker Compose ausführen ließ. Bemerkenswerterweise funktionierte hingegen der Start per Kommandozeile, also per „docker run…“. Und das, obwohl das Compose-File auch nur diejenigen Parameter enthielt, die beim manuellen Start übergeben wurden. Definitiv unlogisch, aber andererseits wollte ich mich auch nicht mit Debugging eines MongoDB-Images beschäftigen.
Und da gab es ja noch ein „offizielles“ MongoDB-Image, einfach nur „mongo“ genannt. Verwaltet von der Docker-Community, basierend auf den offiziellen Quellen, ausgestattet mit einer etwas ausführlicheren Dokumentation. Also hätten wir nun ein irgendwie „super-offizielles“, herausgegeben von MongoDB, und ein „offizielles“ MongoDB-Community-Server-Docker-Image. Immerhin hatte ich mit Letzterem mehr Glück, denn dies ließ sich ohne weitere Umstände mit einem Docker-Compose-File einrichten und starten:
services:
mongodb:
#image: mongodb/mongodb-community-server:8.0.5-ubi9 # does not work!!!
image: mongo:8.0.5
ports:
- "27018:27017"
volumes:
- ./data:/data/db
environment:
- MONGODB_INITDB_ROOT_USERNAME=user
- MONGODB_INITDB_ROOT_PASSWORD=pass
Glaube keinem Benchmark!
Wie üblich bei Benchmarks gibt es einige Einschränkungen. Zunächst wäre da die virtuelle Maschine selbst, es handelt sich nur um eine kleine VM, die hier während der Entwicklung als Datenbank-Server dient. Auf einer weiteren, von den Ressourcen her etwa identischen VM sollte der Benchmark laufen. Beide VMs befinden sich auf demselben Host, was immerhin eine schnelle Netzwerkverbindung ermöglicht. In der Praxis wären Datenbank-Server jedoch von einem ganz anderen Kaliber, und somit nicht mit nur zwei (virtuellen) CPUs und 8 GB RAM ausgestattet, anstatt von klassischen Festplatten kämen SSDs zum Einsatz, und so weiter. Ich habe mich dennoch einerseits für die Ausführung und andererseits für die Veröffentlichung der gewonnenen Daten entschieden, da beide Kontrahenten unter denselben Randbedingungen getestet wurden. Dies betrifft nicht nur die Hardware, sondern auch die Nutzung innerhalb von Docker-Containern, außerdem ohne weitere Optimierungen, sondern im Auslieferungszustand, quasi MongoDB und FerretDB, wie sie „aus der Tüte fallen“. Insofern scheint mir durchaus eine gewisse Vergleichbarkeit gegeben zu sein.
Benchmark: Tool und Parameter
Für den Benchmark selbst kam das in Go geschriebene Tool „mongodb-benchmarking“ zum Einsatz. Dabei wurde auf alle Tests, d.h. die „Run-All-Sequence“, bestehend aus Insert-, Delete-, Update- und Upsert-Operationen zurückgegriffen, außerdem wurden die Parameter Anzahl der parallelen Threads, Anzahl der Dokumente und die Größe der Dokumente variiert. Die Parameter im Einzelnen:
- Threads: 10 Threads vs. 50 Threads
- Documents: 100.000 Dokumente vs. 1.000.000 Dokumente
- Größe: small vs. large
Die Auswertungen beziehen sich auf die Angabe „mean“, d.h. die mittlere Anzahl an Operationen (inserts, deletes, updates, upserts) pro Sekunde.
Ein typischer Aufruf des Benchmark-Tools sah z.B. so aus, hier ausgeführt mit dem MongoDB-Server, der auf Port 27018 lauschte:
../mongo-bench -threads 10 -docs 100000 -uri mongodb://gatow.geschke.net:27018 -type runAll
Später hatte ich das Benchmark-Tool dann noch ein wenig modifiziert, um die Bezeichnungen der CSV-Dateien anpassen und um den Parameter „type“ – wie in der Dokumentation angegeben – für den „runAll“-Test nutzen zu können, außerdem liefen die einzelnen Benchmarks hintereinander mittels Shell-Skript.
Benchmark-Ergebnisse: MongoDB vs. FerretDB
Insgesamt sind damit doch einige Daten und infolge dessen Ergebnis-Diagramme zusammen gekommen, von denen ich nur einige exemplarisch herausstellen möchte. Alle weiteren werde ich dem Artikel im Anhang beifügen.
Zunächst die Ergebnisse für 100.000 Dokumente kleiner Größe bei 10 Threads:
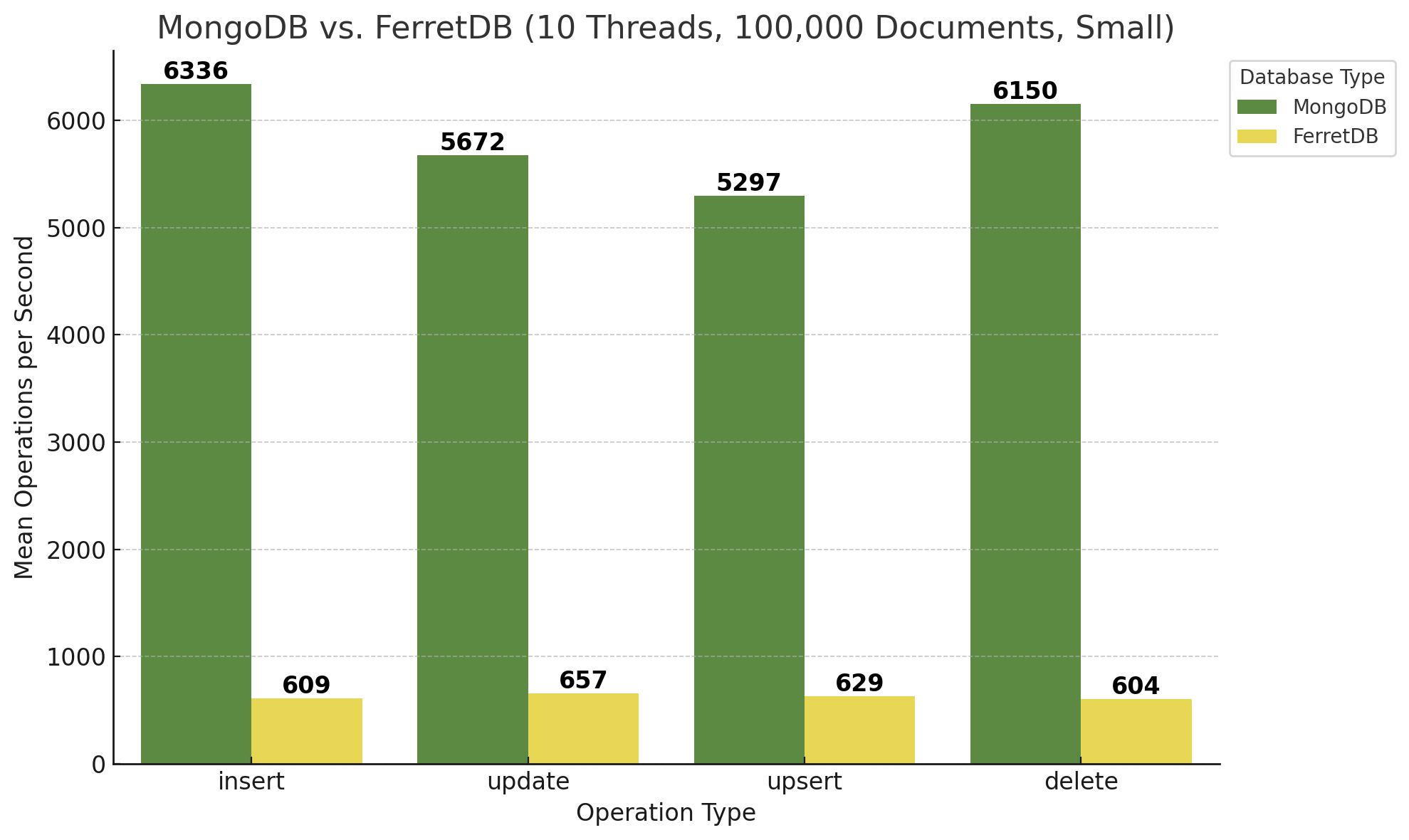
Auf den ersten Blick schneidet FerretDB gegenüber MongoDB dabei schlecht ab. MongoDB erreicht ungefähr die zehnfache Anzahl an Operationen pro Sekunde, je nach Typ der Operation. Updates und Upserts sind für MongoDB vermutlich etwas aufwändiger, bei FerretDB und somit PostgreSQL bleibt die Geschwindigkeit in etwa identisch.
Zum Vergleich dazu die Ergebnisse für größere Dokumente, somit der Einstellung „large“ des Benchmarks:
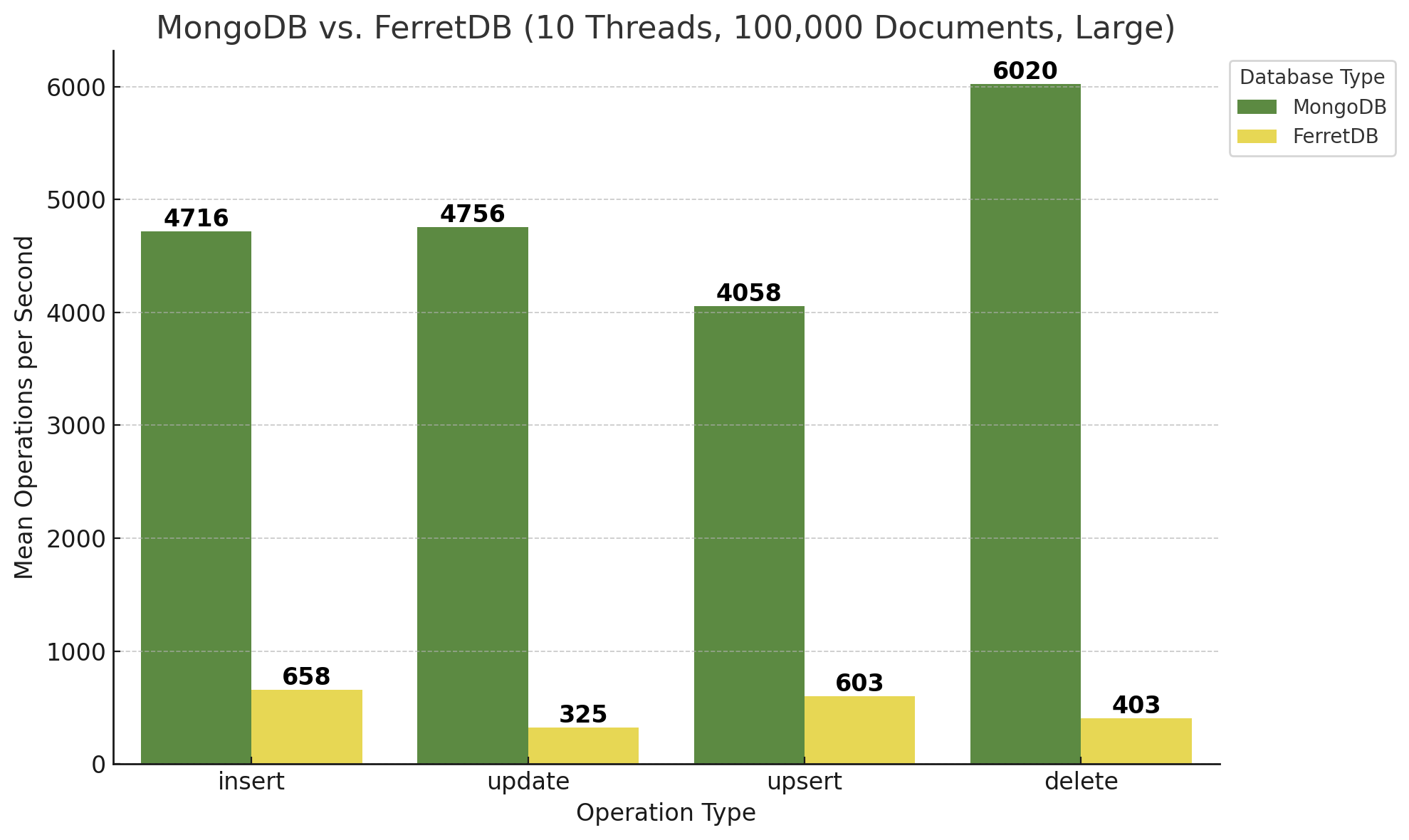
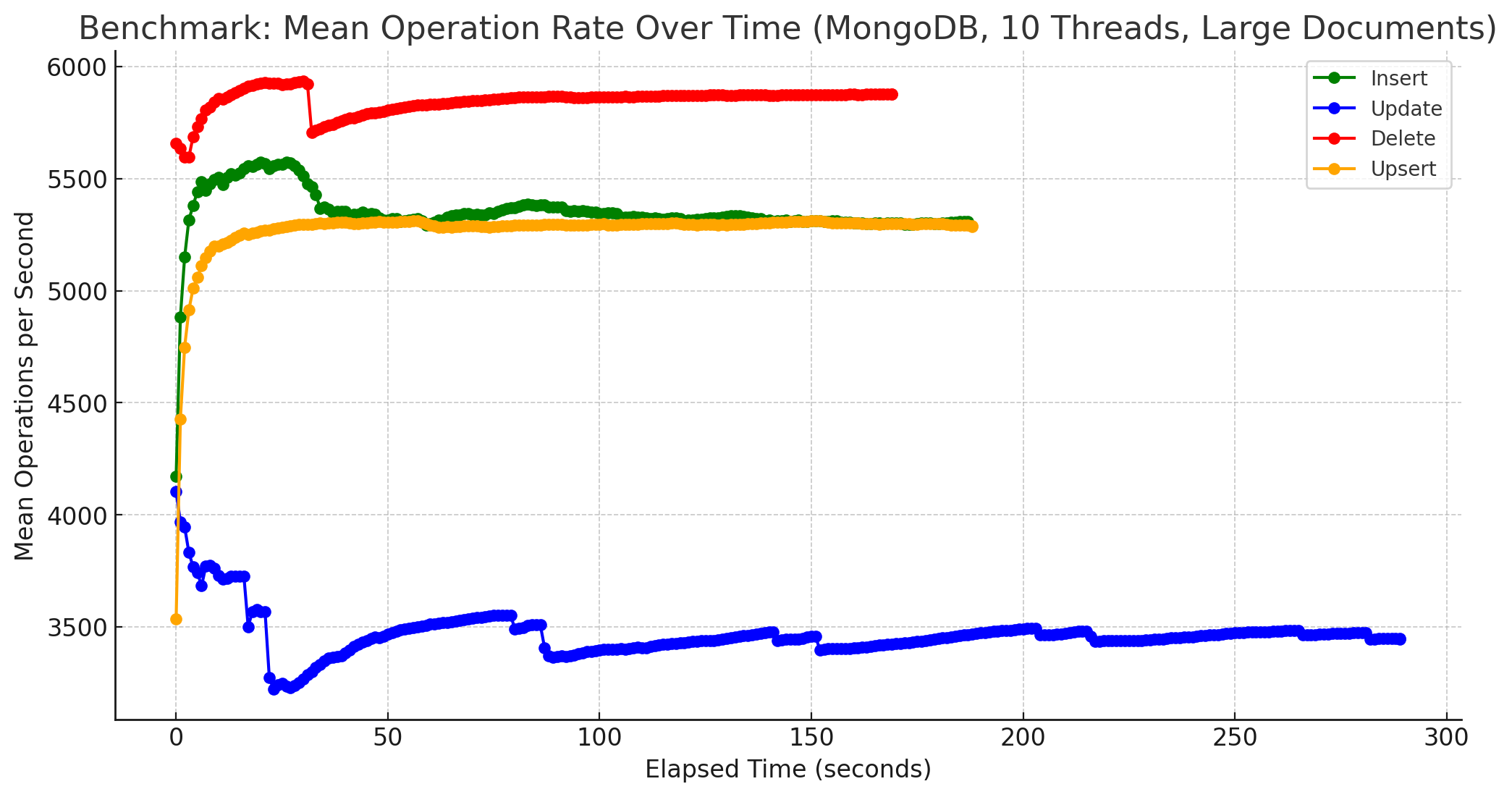
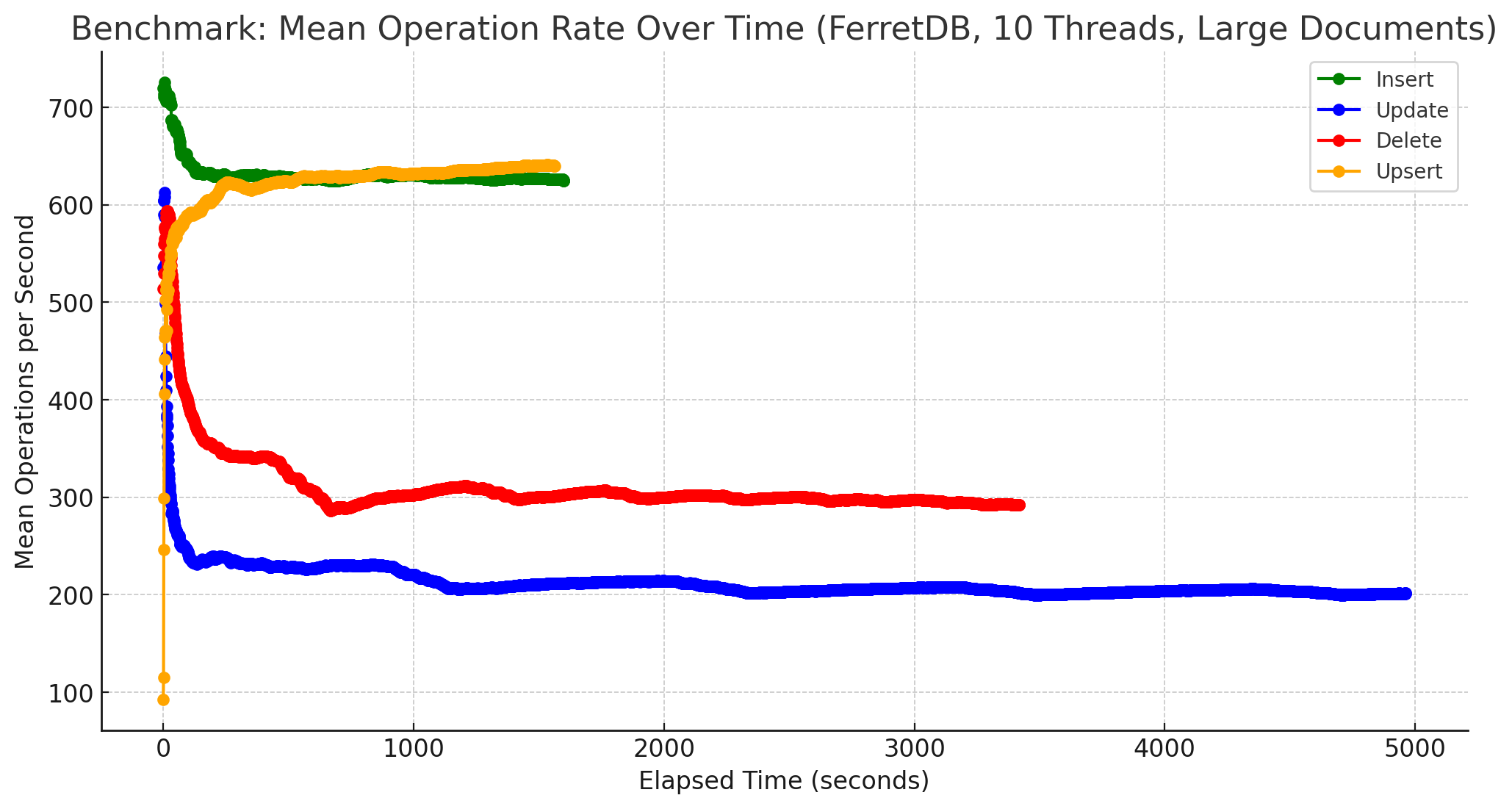
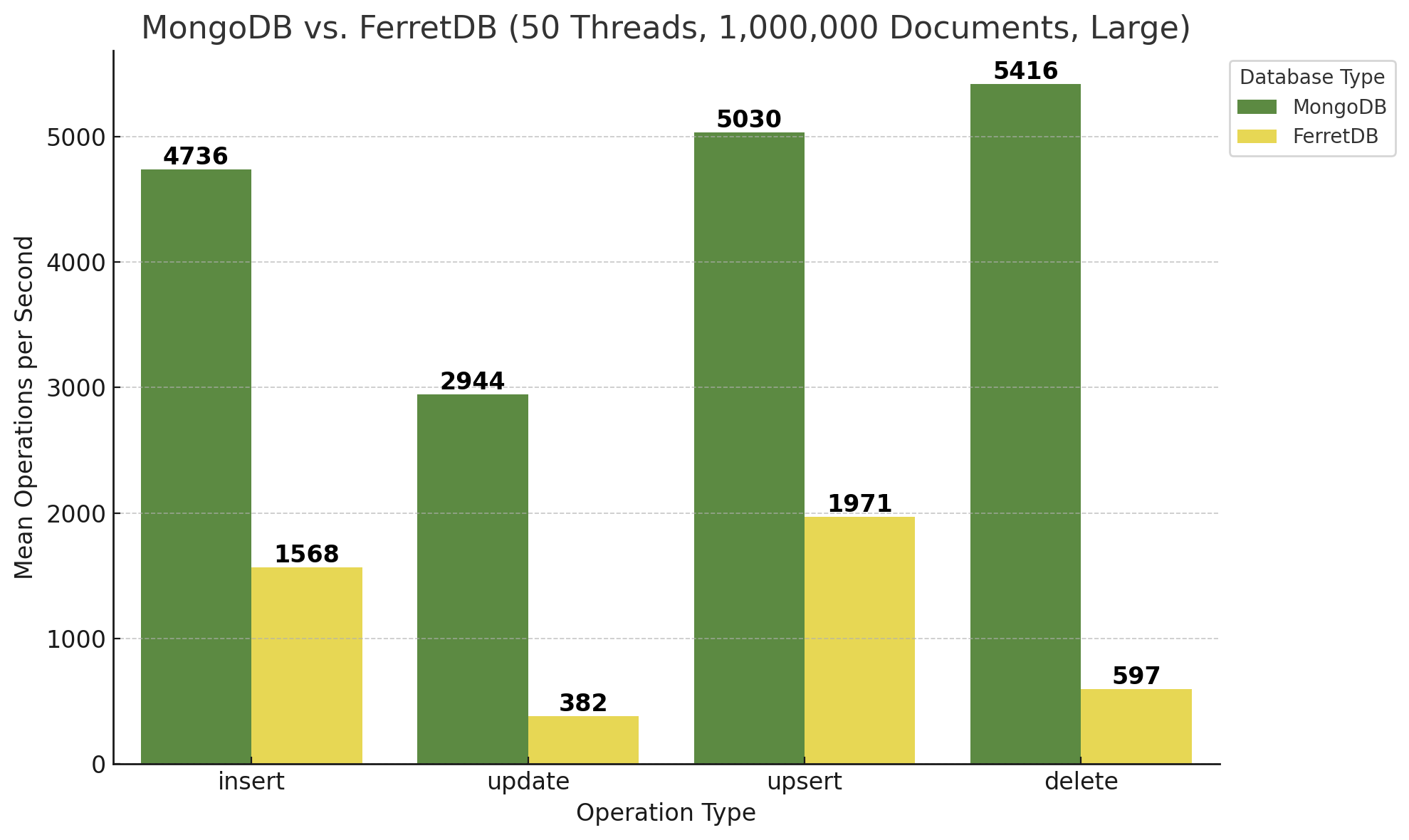
Während FerretDB hier bei den Insert- und Upsert-Operationen in etwa gleiche Ergebnisse zeigt, ist MongoDB zwar immer noch wesentlich schneller, bricht aber etwa bei den Inserts von größeren Dokumenten um ca. 25% ein. Einzig die Delete-Operationen kann MongoDB in ungefähr derselben Geschwindigkeit ausführen wie bei kleineren Dokumenten. FerretDB hingegen ist bei Updates-Operationen nur noch halb so schnell, bei Delete-Operationen verringert sich die Geschwindigkeit um ungefähr ein Drittel.
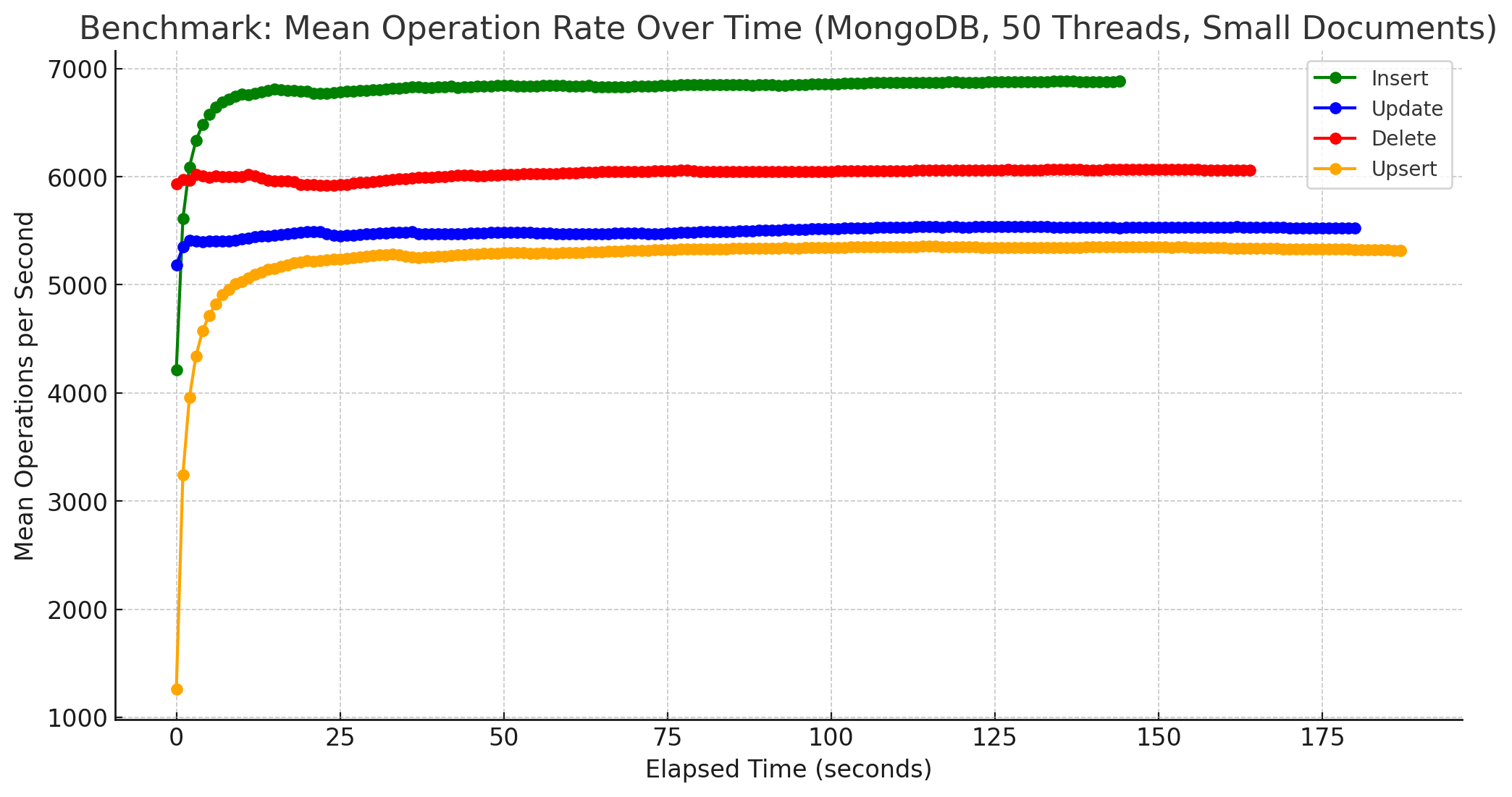
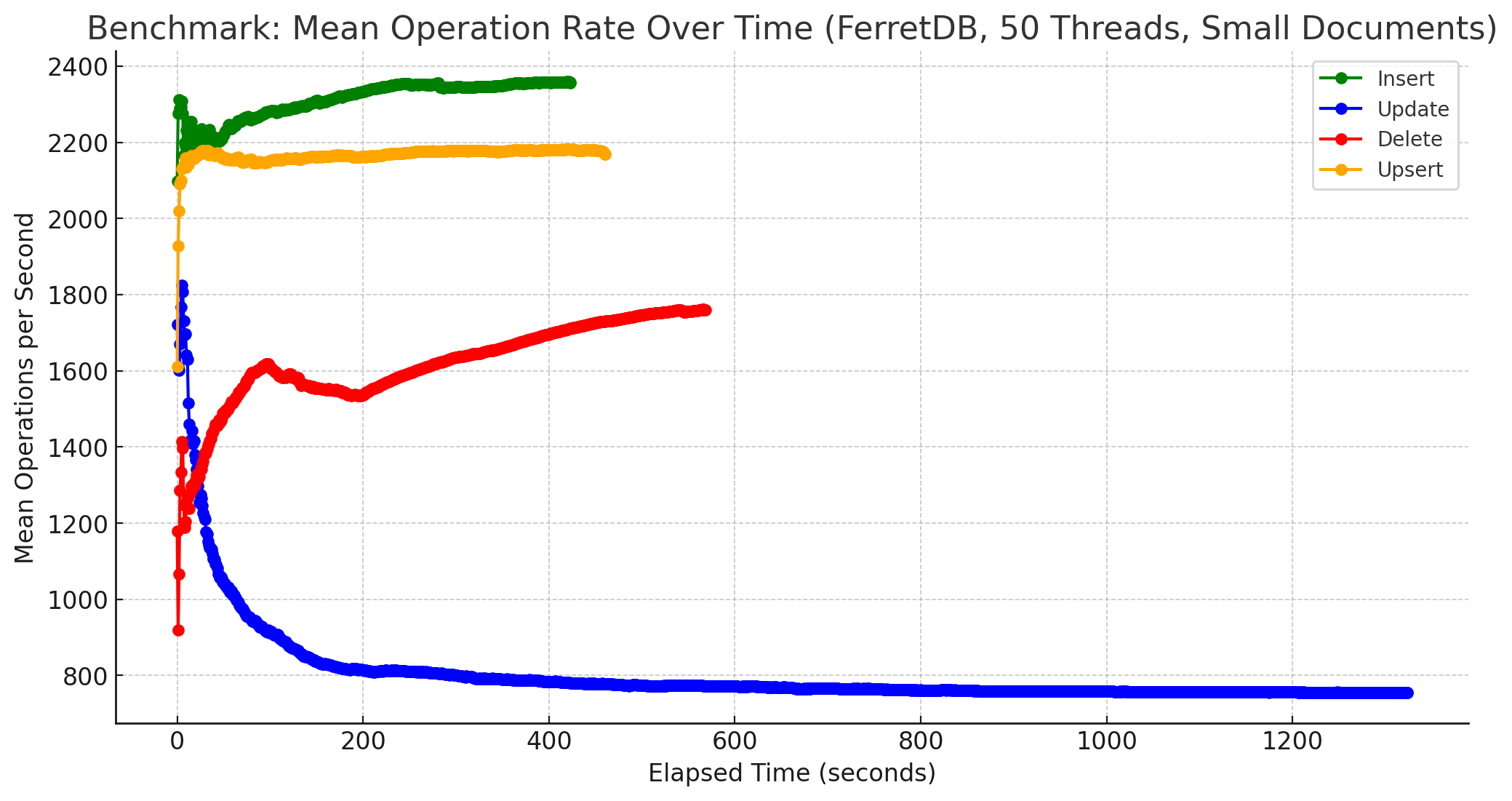
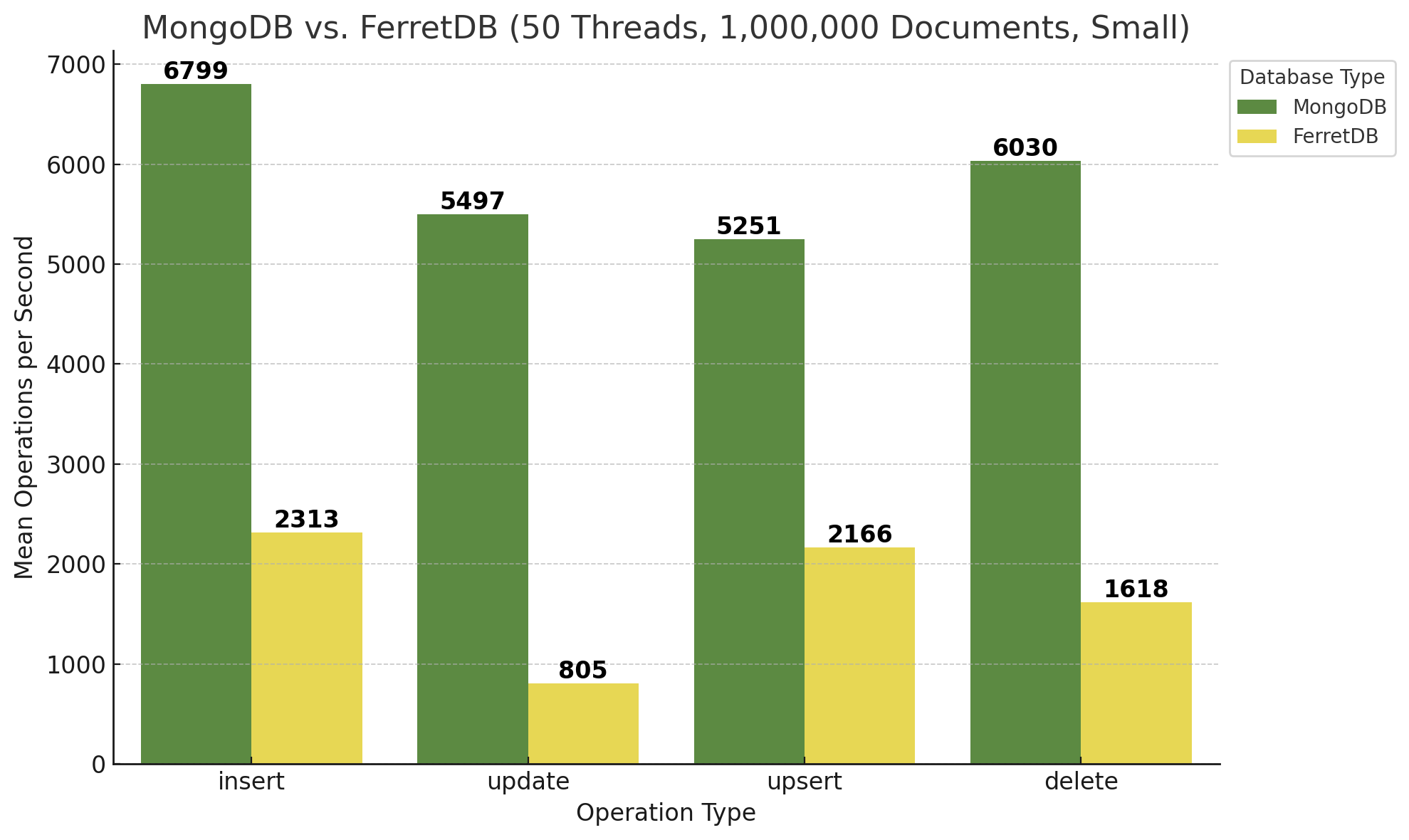
Interessant ist auch die Betrachtung der Ergebnisse bei 50 Threads unter ansonsten gleichen Bedingungen, zunächst für kleine Dokumente:
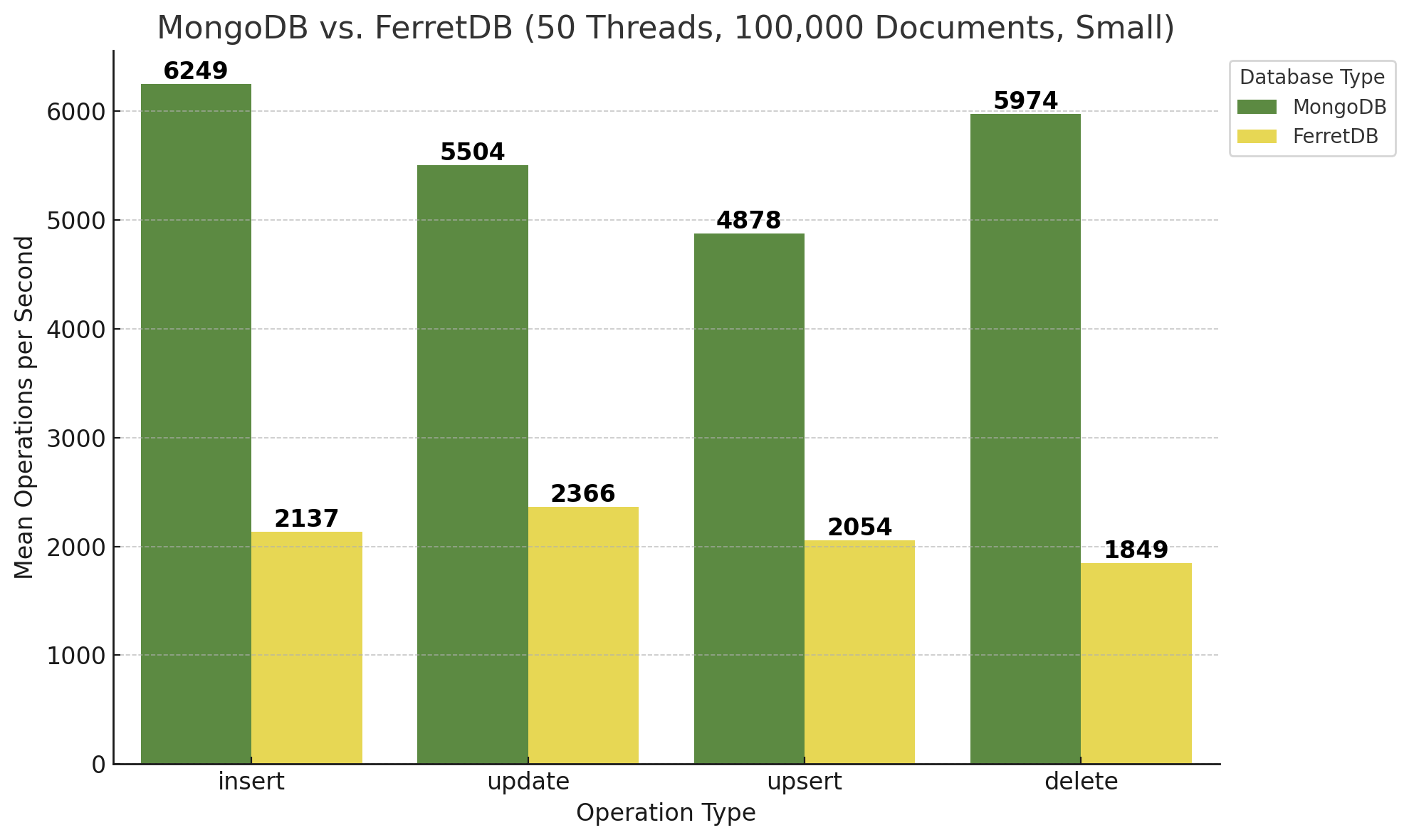
Dasselbe für größere Dokumente:
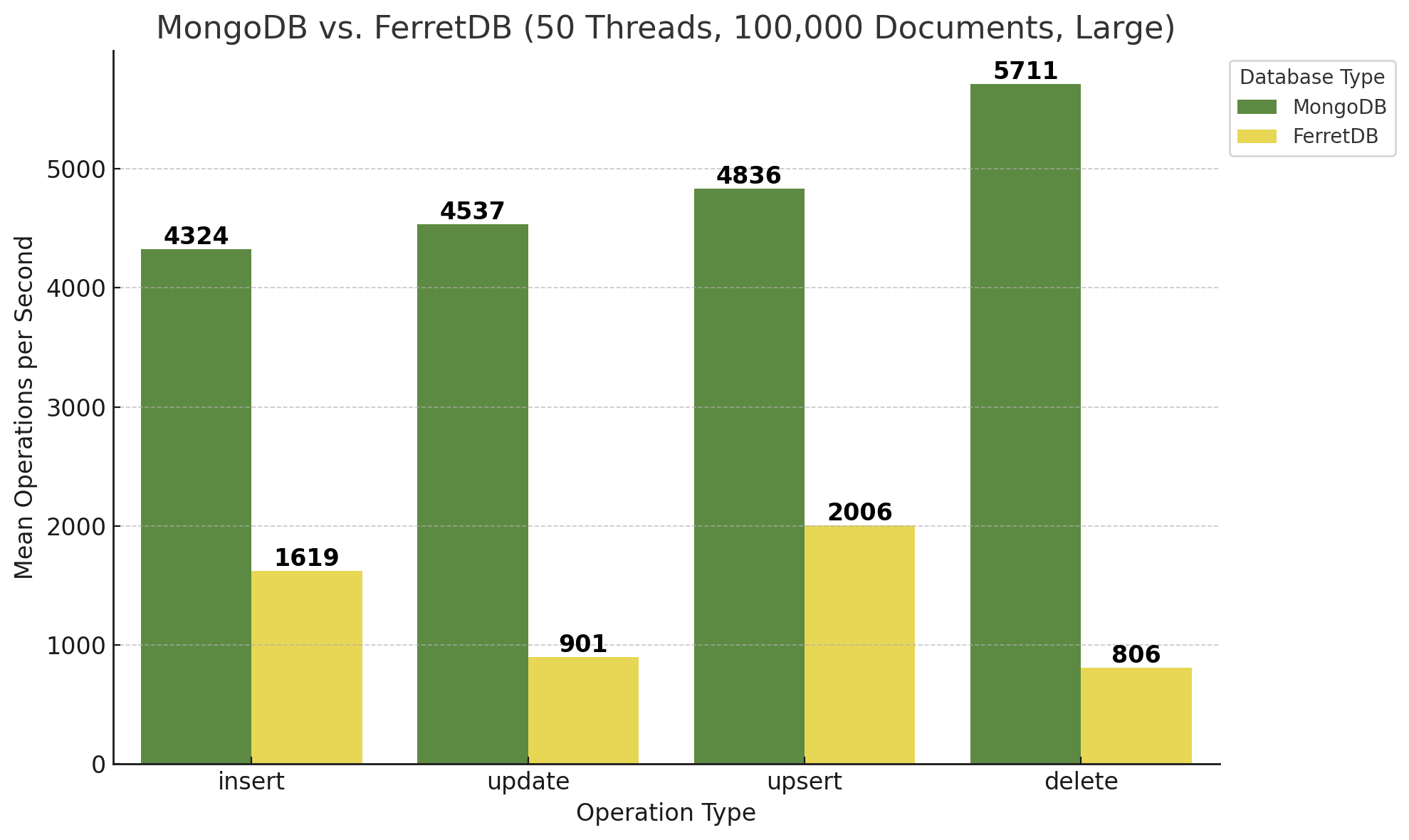
FerretDB ist zwar nach wie vor absolut gesehen langsamer, aber hat doch sehr stark aufgeholt! Bezogen auf die Insert-Operationen legt FerretDB bei 50 Threads ordentlich zu, was auf eine gute Skalierbarkeit des PostgreSQL-Backends schließen lässt. Auch ist die Load der Datenbank-VM während des Benchmarks von MongoDB und 50 Threads enorm gestiegen, während sie bei FerretDB wesentlich geringere Höhen erreicht hat. Der Vergleich von 10 Threads vs. 50 Threads lässt sich auch in folgendem Diagramm verdeutlichen:
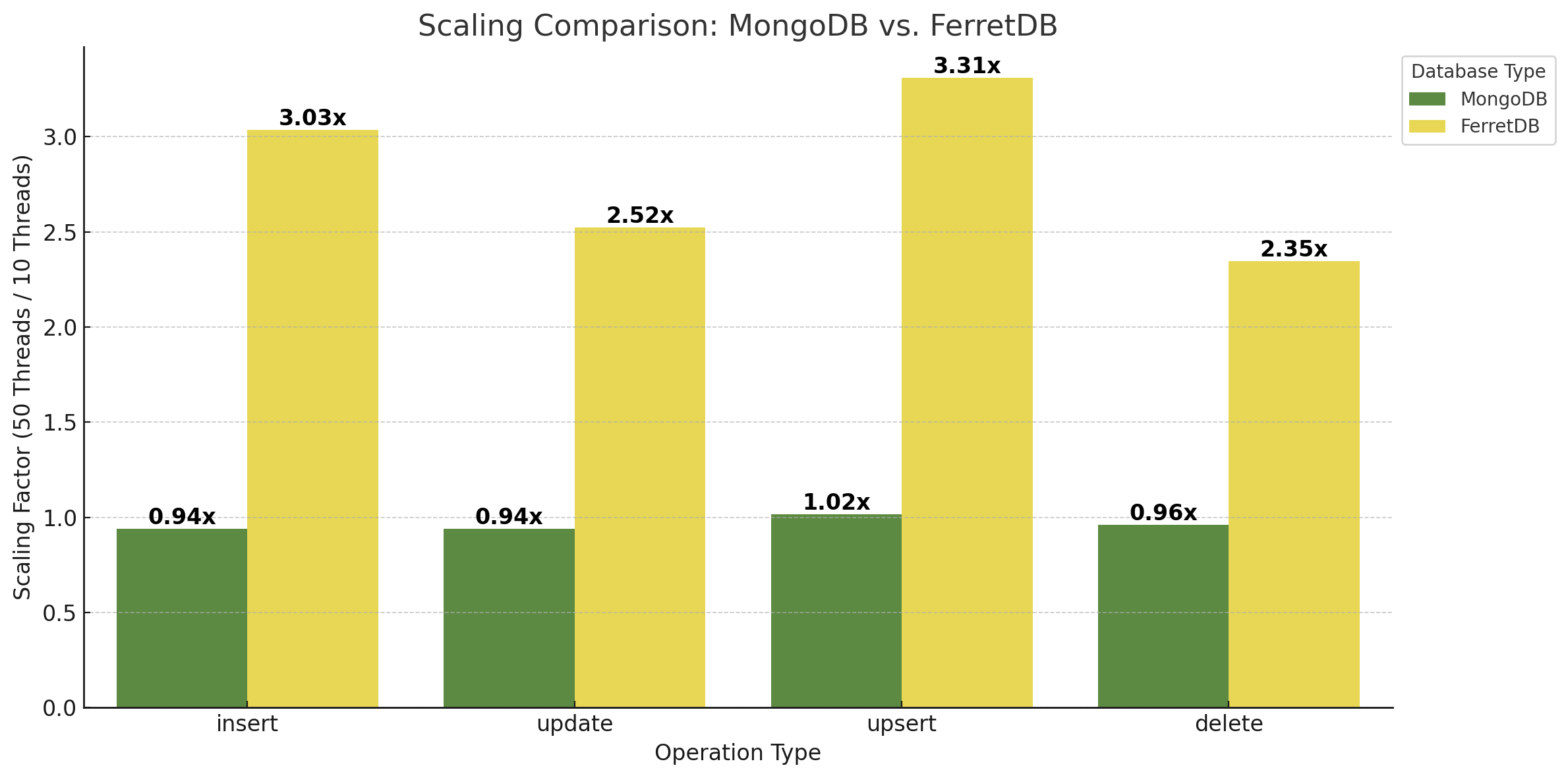
Zur Ermittlung der Faktoren wurden die Mittelwerte von kleinen und größeren Dokumenten und der Dokumentenanzahl herangezogen. MongoDB bleibt ungefähr gleich bzw. wird ein wenig langsamer, während FerretDB und somit PostgreSQL deutlich an Performance gewinnt, d.h. mehr Operationen pro Sekunde ausführen kann. Wie eingangs erwähnt – unter denselben Bedingungen seitens der Hardware bzw. der zugrunde liegenden VM.
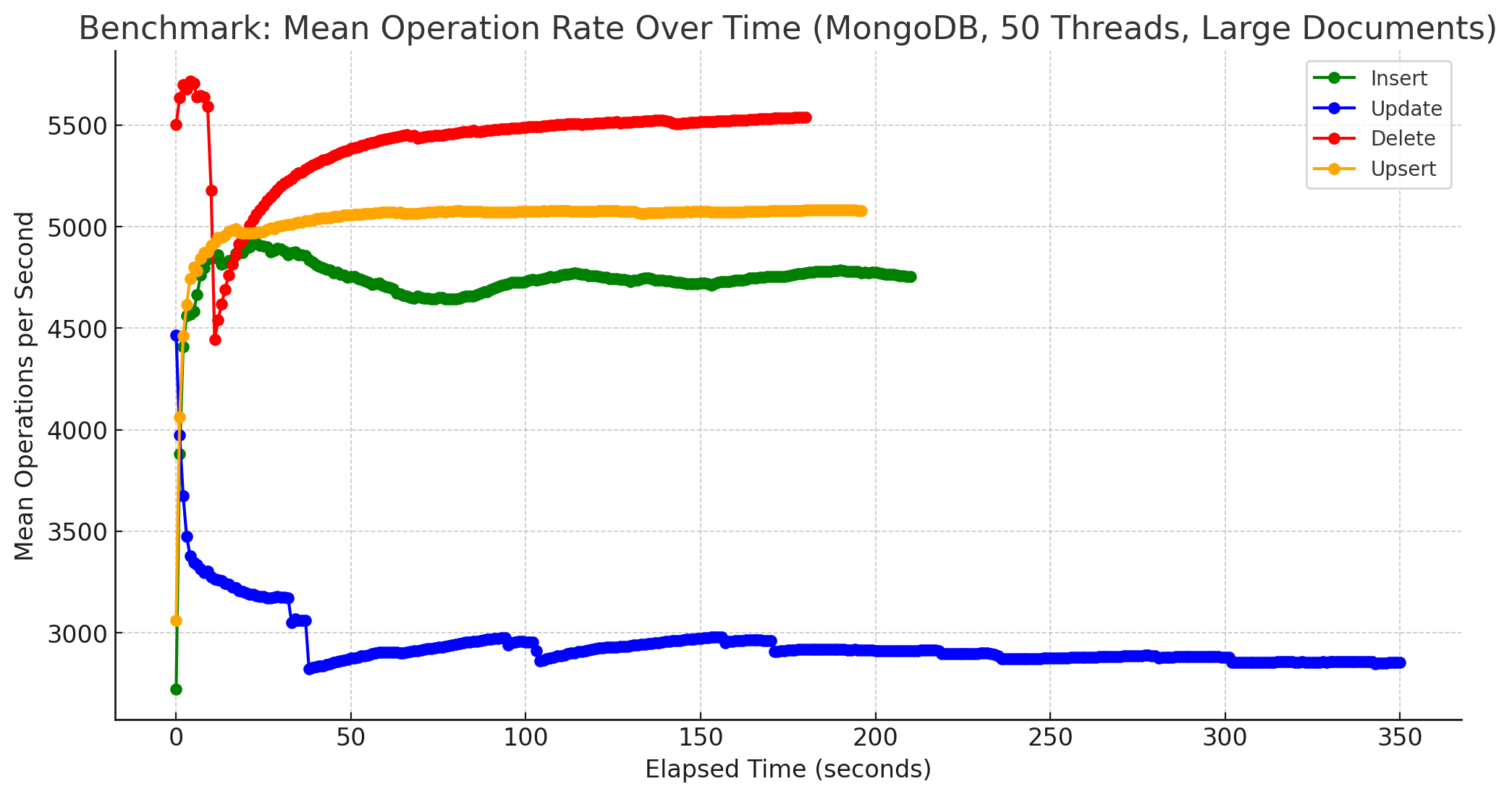
Zum Schluss noch Diagramme, die die Anzahl der Operationen im Zeitverlauf bei 1.000.000 Dokumente zeigt, zunächst für MongoDB und kleiner Größe:
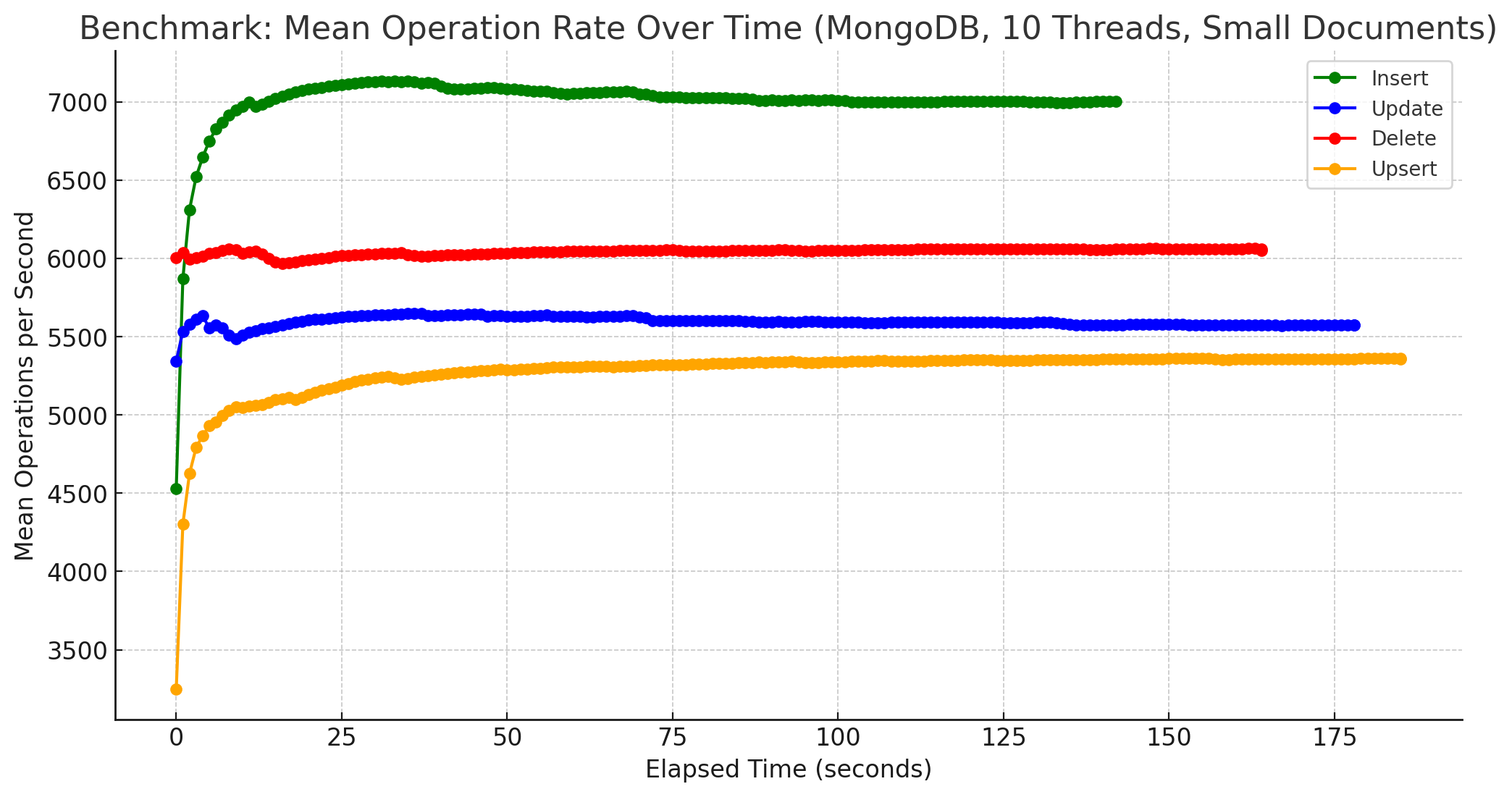
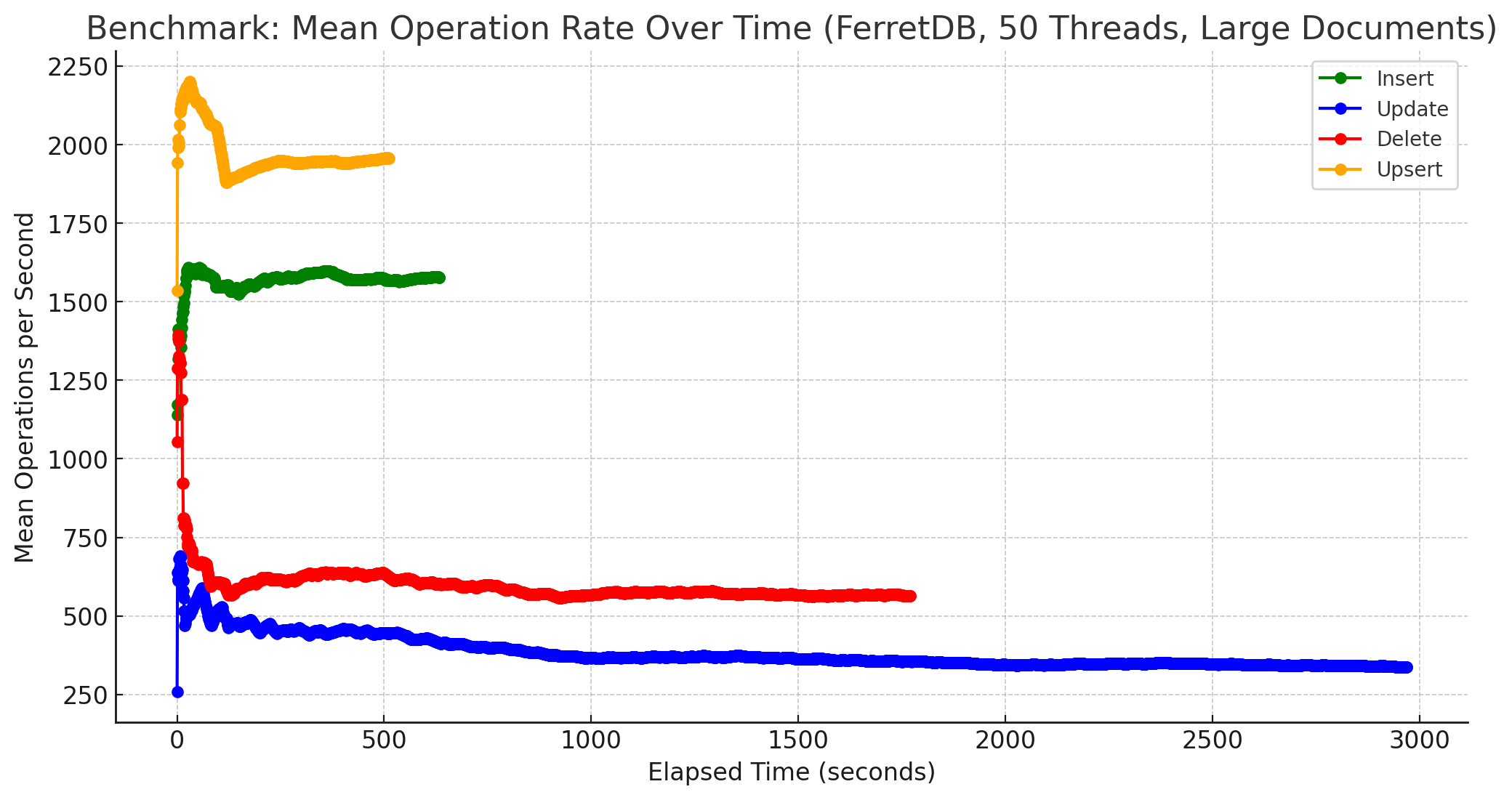
Und für FerretDB:
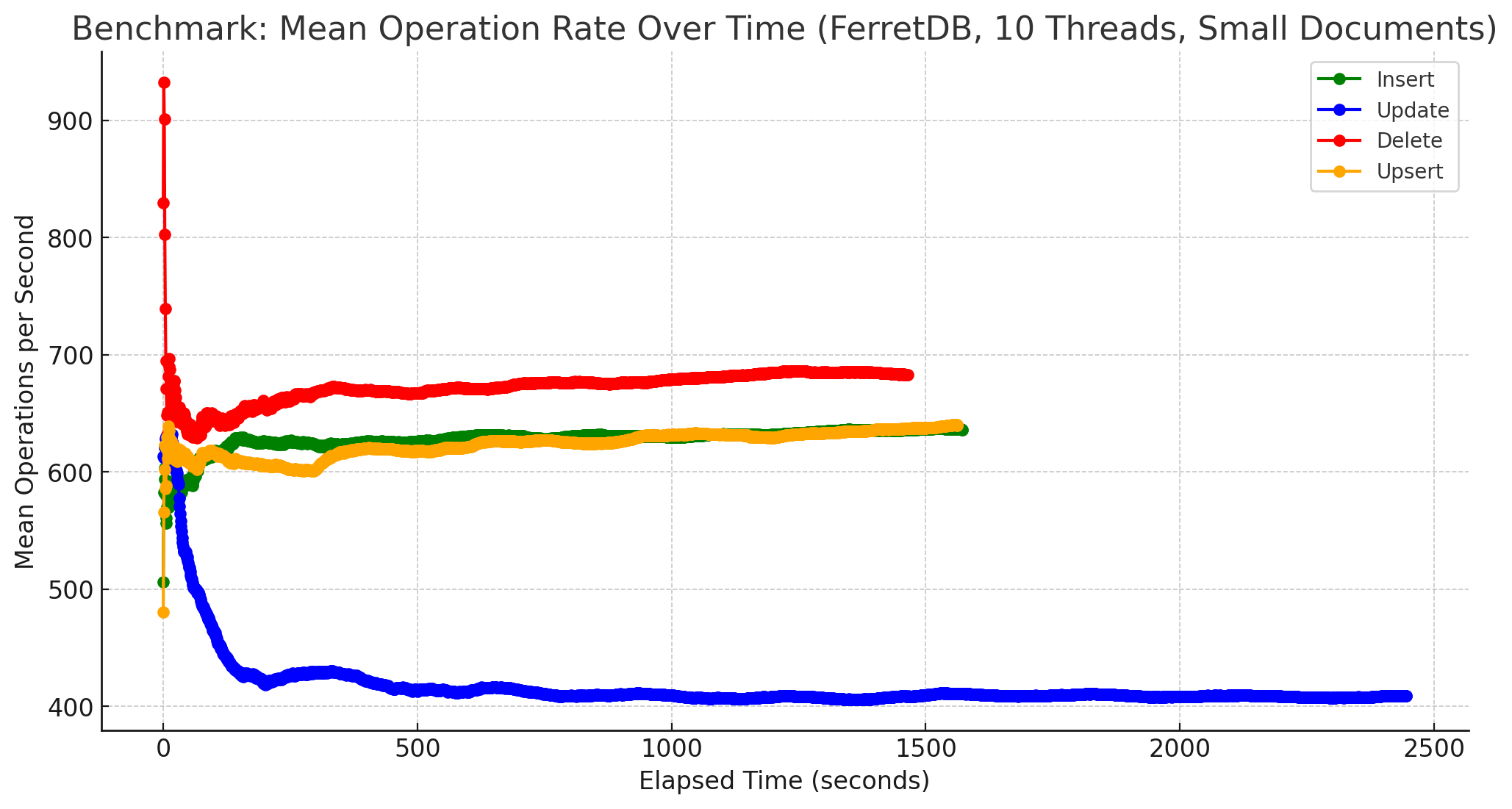
Zugegebenermaßen sind diese Diagramme etwas suboptimal, da aus den vorhandenen Daten gewonnen. Besser wäre es gewesen, die Benchmarks dafür mittels Parameter -duration eine gewisse Zeit laufen zu lassen und daraus die Werte zu ermitteln. Hierbei ging es mir aber nicht um eine Darstellung der absoluten Anzahl an Operationen pro Sekunde, sondern um einen anderen Aspekt. Bei beiden, sowohl MongoDB als auch FerretDB wurden die Messungen für 1 Mio. Dokumente problemlos ausgeführt. Von der Stabilität her gab es somit keine Probleme, FerretDB benötigte erwartungsgemäß eine längere Zeit, bis alle Operationen für alle Dokumente ausgeführt worden waren, lief jedoch ebenso stabil bis zum Ende durch. Zum anderen gab es, zumindest bei kleinen Dokumenten, auch keine größeren Einbrüche während der Laufzeit. Die Anzahl an Operationen pendelte sich im Laufe der Zeit um einen Wert herum ein, der auch in etwa beibehalten wurde. Dies gilt auch weitestgehend für größere Dokumente, einzige Ausnahme bilden Update-Operationen bei MongoDB, siehe dazu das Diagramm weiter unten.
Fazit und Bewertung
Wie sind nun diese Ergebnisse zu interpretieren? Natürlich ist MongoDB zunächst einmal schneller, teilweise sogar um den Faktor 10. Ist FerretDB deshalb also überflüssig? Meines Erachtens ist genau das Gegenteil der Fall! Einerseits wären da die Lizenzbedingungen. FerretDB stellt eine vollständige Dokumentendatenbank als Open-Source-Lösung zur Verfügung. Allein dieser Umstand ist ein wesentlicher Unterschied zu MongoDB, so dass sich daraus bereits eine Daseinsberechtigung begründet. Aus der Geschichte heraus – auch zu dem Zeitpunkt, als z.B. MySQL entwickelt wurde, gab es bereits SQL-Datenbanken kommerzieller Natur, die erfolgreich und von der Performance her wesentlich besser waren. Dennoch haben MySQL und dessen Ableger ihren Siegeszug angetreten und sind in einigen Bereichen wie etwa der Nutzung in Web-Anwendungen sogar führende und bevorzugte Lösungen.
Auch nicht außer Acht gelassen werden darf die bislang eingesetzte Zeit für die Entwicklung. Während die erste Veröffentlichung von MongoDB bereits im Jahre 2009 stattgefunden hat, stammen die Anfänge von FerretDB aus 2021, eine Version 1.0 wurde 2023 erreicht, und die erste Version, die auf Microsofts DocumentDB basiert, gibt es zum Zeitpunkt des Schreibens dieses Artikels erst seit wenigen Wochen. Die Entwicklung ist dabei durchaus rasant, so mischen nicht nur einige Größen aus dem Open-Source-Umfeld mit, sondern eben auch Microsoft mit der dahinter steckenden Manpower und Erfahrungen im Praxiseinsatz beim Azure Cosmos DB Service.. In der Community findet FerretDB seit Erscheinen der Version 2.0 ebenfalls einigen Anklang, d.h. das Interesse ist groß, insofern ist zu vermuten, dass sich dies auch in der weiteren Entwicklung widerspiegelt.
Außerdem darf nicht vergessen werden, dass der hier eingesetzte Benchmark zwar Anhaltspunkte über die Geschwindigkeit liefert, aber die Operationen alles andere als ein realistisches Szenario darstellen. Interessant wären z.B. Find-Operationen auf komplexeren Dokumenten mit mehreren Ebenen, oder überhaupt eine stärkere Gewichtung von Lese-Operationen, die sich an den Anforderungen aus der jeweiligen praktischen Anwendung ergeben.
Und nicht zuletzt kommt es letztlich nicht auf die absolute Geschwindigkeit und das letzte Quäntchen Performance an, sondern eher darauf, dass eine Lösung schnell genug ist für die entsprechende Anwendung. Und falls FerretDB einmal doch nicht ganz schnell genug sein sollte, etwa für eine erfolgreiche, kommerzielle Lösung, spricht natürlich auch nichts dagegen, in diesem Fall auf MongoDB und seine Lizenzierung zu setzen. Gerade die angestrebte Interoperabilität und Standardisierung ermöglichen eine solche Herangehensweise.
Auf jeden Fall werde ich die Zukunft von FerretDB gespannt verfolgen und als Entwickler auch weiterhin verwenden. Letzteres angesichts des Open-Source-Gedankens mit einem subjektiven, aber sehr guten Gefühl.
Anhang
Zunächst alle Diagramme für die Benchmark-Läufe mit 1.000.000 Dokumenten:
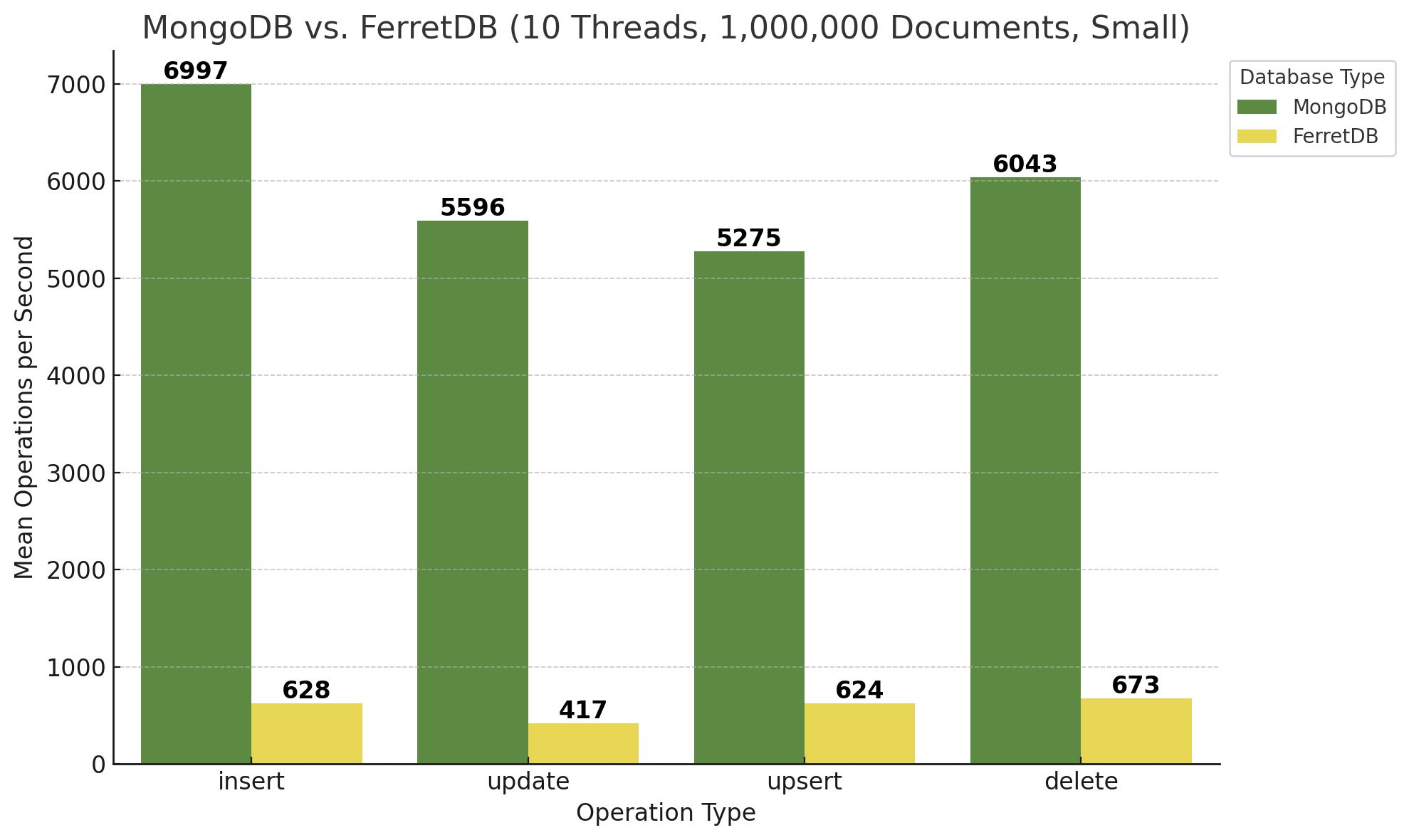
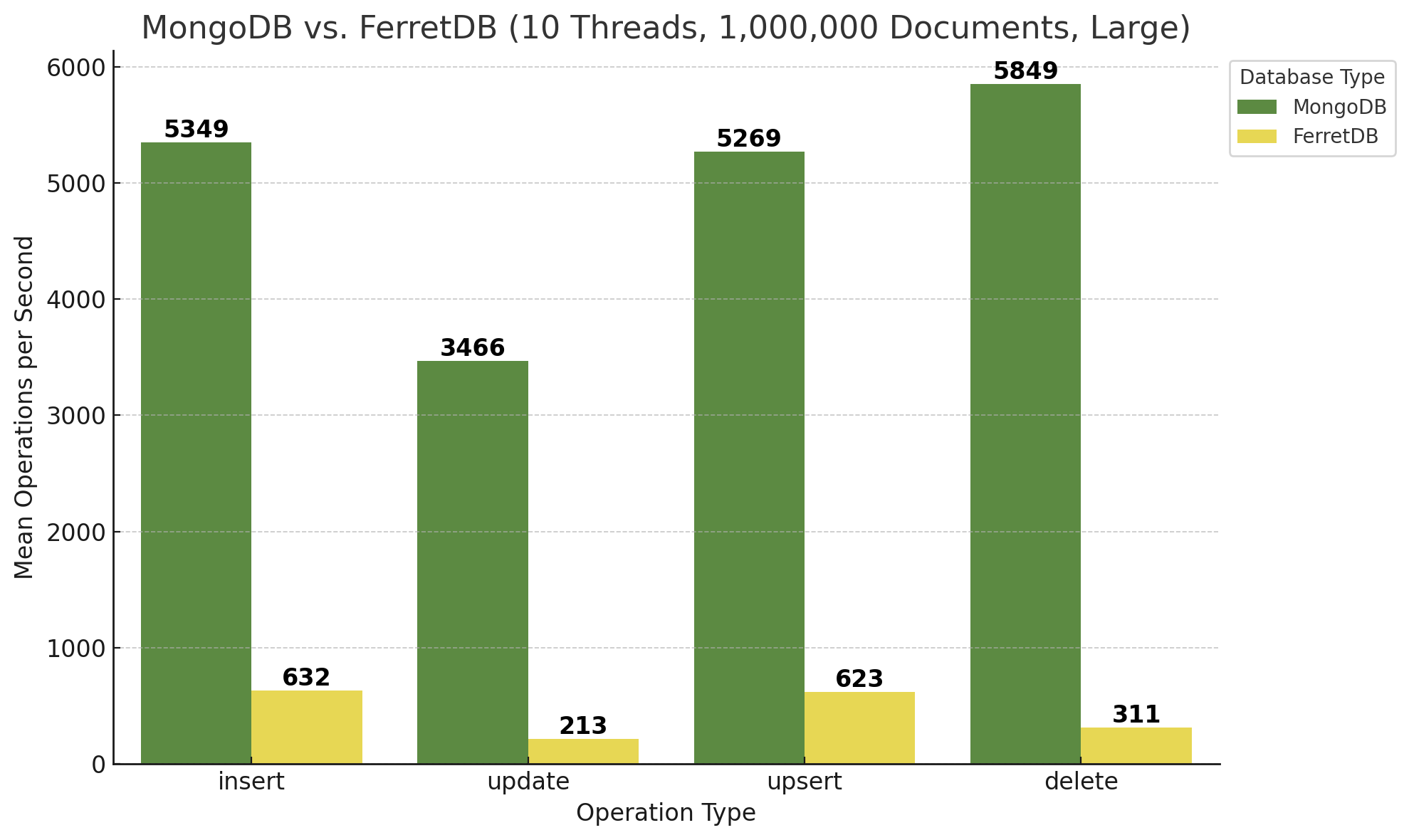
.
Und zu guter Letzt die Verlaufsdiagramme: